Table of Contents
ToggleAsk any sales leader what separates a great first meeting from a forgettable one, and the answer is rarely charisma, it’s preparation.
Who’s in the room. What their company cares about. What’s happened in the account so far. Which discovery questions will actually land instead of wasting the first ten minutes.
The trouble is that this kind of preparation is unglamorous, time-consuming, and scattered across a half-dozen systems: a CRM record here, a LinkedIn profile there, an old email thread, a colleague’s Slack message from three months ago.
None of it is hard to find individually. All of it, together, takes real time to assemble, and that time comes directly out of a rep’s calendar before every single first call.
Across a ninety-person sales organization, that time cost compounds fast. But the bigger problem wasn’t just the hours lost, it was the inconsistency. Some reps were meticulous, building thorough briefs before every meeting. Others, buried under a full calendar, walked in with a skim of the CRM and a hope that the conversation would fill in the gaps. The result was a wide spread in meeting readiness that had nothing to do with skill and everything to do with time pressure.
Breaking Down Where the Time Actually Went
Manual first-meeting prep isn’t one task — it’s several smaller research tasks stitched together, each pulled from a different source and each competing for the same scarce block of time before a call.
| Prep Task | Typical Source | Why It’s Time-Consuming |
| Attendee research | LinkedIn, email signatures, past meeting notes | Requires cross-referencing multiple attendees, each with a different role and context |
| Account history | CRM, deal notes, internal Slack threads | Often incomplete or inconsistently logged by whoever last touched the account |
| Company/industry context | Company website, news search, analyst reports | Requires judgment about what’s actually relevant to the conversation |
| Discovery question planning | Rep’s own experience, sales playbooks | Varies heavily by rep tenure and how recently they reviewed the playbook |
| Agenda structuring | Ad hoc, often skipped entirely | Frequently the first thing cut when time runs short |
That last row matters more than it might seem. When reps run out of prep time, agenda-building is usually what gets dropped first — which means the meetings with the least prep time are also the ones most likely to wander without structure. The problem compounds exactly where it hurts most.
Why This Was an Organizational Problem, Not Just an Individual One
At the scale of a single rep, inconsistent prep is a minor inefficiency. At the scale of ninety reps, it becomes a management and brand problem:
- Uneven customer experience. A prospect meeting with a well-prepared rep and a prospect meeting with a rushed one are getting materially different experiences of the company — even if both reps are equally skilled.
- No reliable floor. Sales leadership had no consistent baseline for what “meeting-ready” meant across the team, which made it hard to coach to a standard or diagnose why some deals stalled early.
- Tenure bias in outcomes. Newer reps, who most needed strong first meetings to build credibility, were often the same reps with the least efficient research habits, compounding a disadvantage that had nothing to do with their potential.
The Goal
The brief for this project was intentionally narrow and outcome-focused:
- Reduce the manual time reps spent assembling first-meeting prep from scattered sources.
- Standardize meeting readiness so that quality no longer depended on an individual rep’s workload, tenure, or diligence that week.
Notably, the goal was not “make reps sound smarter” or “increase win rate” as a first-order target — those are plausible downstream effects, but the team was disciplined about measuring what they could measure now, and treating the rest as a hypothesis to validate later rather than a number to promise upfront.
This distinction between efficiency goals and effectiveness goals is worth dwelling on, because it shaped everything downstream — from what the agent was designed to output, to what got reported as the outcome.
| Goal Type | Question It Answers | Measurable Now? |
| Efficiency | Does this save reps time? | Yes, directly, via time tracking or self-report |
| Effectiveness | Does this make meetings better? | Not yet — requires a quality rubric and observation |
| Business outcome | Does this move win rate? | Not yet — requires a longer feedback loop across the full deal cycle |
Starting with the efficiency goal wasn’t a limitation of ambition, it was a deliberate sequencing choice. You can’t credibly claim a win-rate improvement without first confirming reps are actually using the tool and getting real time back. Efficiency gains are the leading indicator; effectiveness and business outcomes are the trailing ones.
What Was Built
The First-Meeting Brief Agent is one of three agents in the firm’s Sales Research Suite — a set of purpose-built agents designed around distinct moments in the sales workflow rather than one general-purpose assistant.
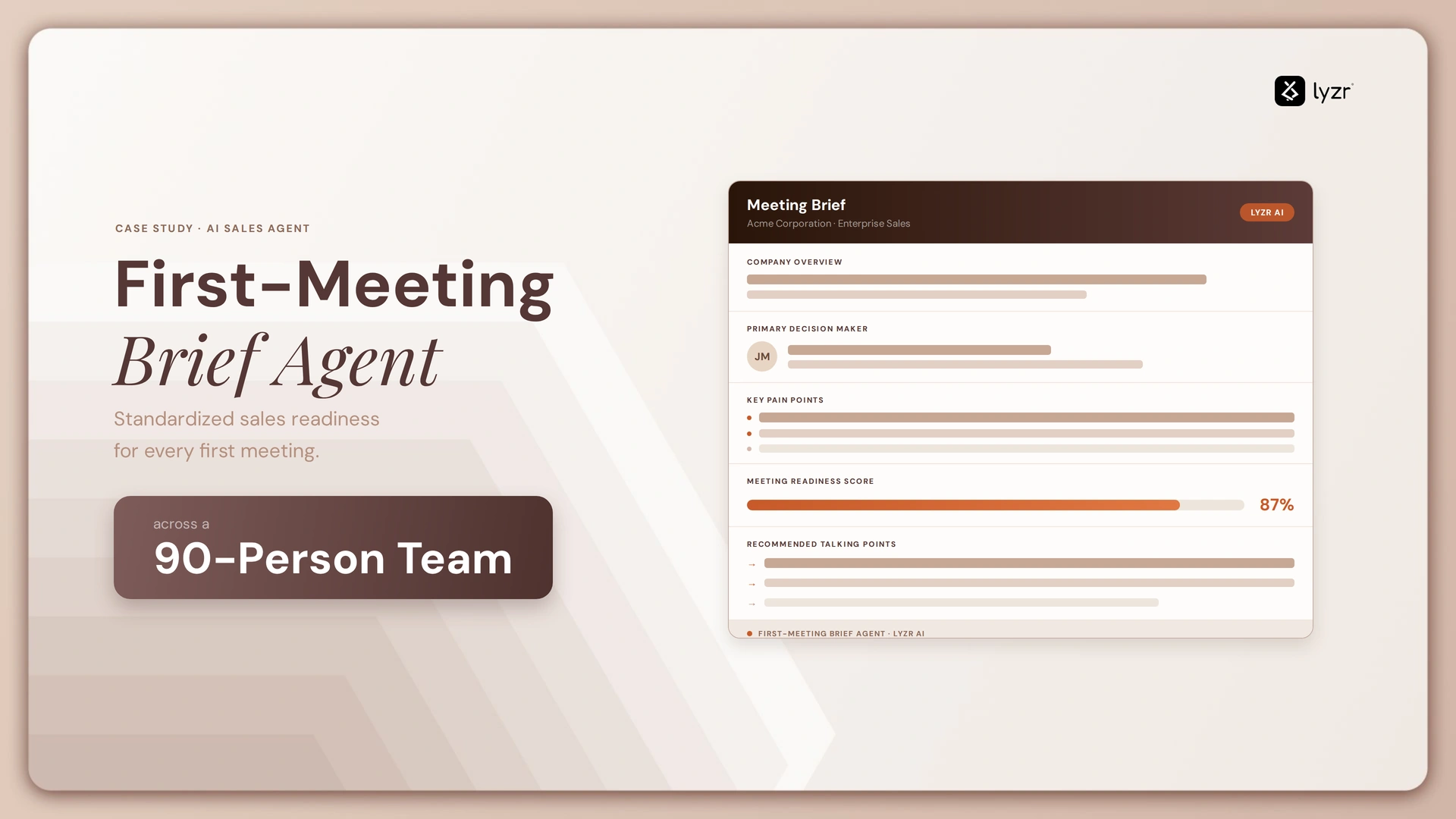
On demand, ahead of a scheduled first meeting, the agent assembles a single structured brief containing:
| Brief Section | What It Contains | Replaces |
| Attendee context | Who’s attending, their role, and relevant background | Manual LinkedIn and email-signature research |
| Account background | Company context and relevant account history | Digging through CRM notes and past threads |
| Discovery angles | Suggested questions and talking points tailored to the account | Rep’s own memory of the playbook, applied ad hoc |
| Proposed agenda | A starting structure for the meeting itself | The step most often skipped under time pressure |
Design Choices That Made This Work
A few choices in how the agent was scoped and positioned appear to matter as much as the underlying technology:
1. A single, well-defined moment. Rather than trying to be a do-everything research assistant, the agent is built around one specific trigger, a scheduled first meeting, and one deliverable, the brief. A rep isn’t opening a general-purpose tool and hoping for something useful; they’re triggering a specific, predictable output tied to something already on their calendar.
2. A fixed structure, not a freeform answer. The brief always has the same four sections, in the same order. That consistency is itself part of the value: reps learn to expect and scan the brief the same way every time, the same way they’d expect a CRM record to have the same fields every time.
3. On-demand, not always-on. The agent runs when triggered ahead of a meeting, rather than continuously monitoring or pushing unsolicited updates. This keeps it aligned to a specific moment of need rather than becoming another notification competing for attention.
4. Positioned as part of a suite, not a standalone feature. The First-Meeting Brief Agent is one of three agents in a broader Sales Research Suite. That framing matters: instead of asking “what’s the one AI feature we should build for sales,” the team asked “what are the distinct research tasks a rep repeats across a deal cycle” — and built toward that map, rather than stretching a single generic assistant to cover all of them.
What the Agent Deliberately Doesn’t Do
Just as important as what the agent produces is what it stays out of:
- It doesn’t make the call for the rep on strategy or pricing — discovery angles are suggestions, not scripts.
- It doesn’t attempt to predict deal outcomes or score the meeting’s likelihood of success — that would blur an efficiency tool into a judgment tool, a much higher bar of trust to earn.
- It doesn’t replace the CRM as a system of record — it reads from existing sources and assembles a brief; it isn’t a new place for reps to log information.
Keeping the agent’s job narrow — assemble a brief, don’t make decisions — likely made it easier for a ninety-person sales team to trust and adopt quickly, since the agent isn’t asking reps to defer judgment to it.
The Outcome
What’s Measured
| Metric | Value |
| Time saved per rep, per week | ~1 hour |
| Sales org size | 90 reps |
| Annual time-saved value | Mid-five figures (offshore labor baseline) |
| Deployment status | Live, full team |
Putting the Time Savings in Context
An hour a week per rep sounds modest in isolation, but scaled across a ninety-person organization it compounds into a meaningful chunk of recovered capacity — capacity that would otherwise be spent on research instead of selling. A few ways to think about what that hour actually represents:
- It’s roughly the length of one additional prospect meeting per rep, per week, if that time were redirected to selling activity instead of prep.
- Multiplied across ninety reps, it adds up to the equivalent of more than two additional full-time roles’ worth of hours annually — without adding headcount.
- Because the time saved is concentrated in a specifically low-value, repetitive task (assembling scattered information), it’s a comparatively “clean” efficiency gain — it doesn’t come at the expense of relationship-building or judgment-based work, which are harder to automate without losing something important.
On the Offshore Labor Baseline
The headline number, an estimated mid-five-figure annual value — is deliberately calculated against an offshore labor baseline rather than fully-loaded rep compensation. That’s a conservative choice, not an inflated one: it prices the saved hour at what it would cost to have the research done by someone else, rather than at the (typically higher) value of a quota-carrying rep’s time.
This choice has two practical benefits worth calling out:
- It’s defensible. Because it doesn’t rely on assumptions about what a rep would have “otherwise” done with the freed-up hour, closed more deals, made more calls, or simply worked fewer hours, the number holds up under scrutiny from finance or operations stakeholders who are naturally skeptical of AI ROI claims.
- It understates the likely true value. If the freed-up hour is actually spent on selling activity by a quota-carrying rep, the real value of that hour is almost certainly higher than an offshore labor rate. The reported figure is closer to a floor than a ceiling.
It’s also worth noting this figure is for one of three agents in the suite. The full picture of the Sales Research Suite’s value is larger — this case study focuses specifically on the First-Meeting Brief Agent’s contribution.
What’s Deliberately Not Claimed Yet
The case study is candid about what it doesn’t yet measure:
- Quality uplift — whether briefs actually make reps more effective in the room, not just faster getting there.
- Win-rate impact — whether better-prepared first meetings translate into more closed deals.
This is a meaningful detail for anyone evaluating similar projects. Time saved is the easiest metric to measure and the easiest to challenge as “not the point.” The team’s choice to report only the time-saved number now — while flagging quality and win-rate as open questions — reflects a measurement discipline that’s often missing from AI project reporting: report what you can prove, and label what you can’t yet as a hypothesis, not a result.
| Reporting Choice | What It Avoids |
| Reporting time saved with a conservative baseline | Overstating ROI with optimistic assumptions |
| Explicitly flagging quality/win-rate as unmeasured | Implying causation between a research tool and closed revenue without evidence |
| Framing this as one agent within a suite | Attributing the full suite’s value to a single agent |
What’s Next
The natural next chapter for this case study is closing the two open questions the team has already flagged:
- Does brief quality correlate with meeting outcomes? This likely requires pairing brief usage data with rep or manager feedback on meeting quality, not just self-reported time savings. A structured post-meeting rubric — even a lightweight one — could start to connect brief usage to perceived meeting effectiveness well before win-rate data is available.
- Does better-prepared first meetings move win rate? This is a longer feedback loop — it requires tracking deals from first meeting through to close and isolating the agent’s effect from everything else that influences a deal, from pricing to competitive dynamics to sheer timing. A cohort comparison between heavy and light agent users, controlled for deal size and segment, would be a reasonable next step.
Until those are answered, the honest and useful version of this story is the one told here: an agent that reliably saves a meaningful chunk of time, every week, for every rep, and standardizes the floor of meeting preparation across a ninety-person team. That’s a real result on its own — and a solid foundation for the harder-to-measure gains that may follow.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here