You’ve approved the pilot. The demos went well. Then someone from Legal walks in with one question:
“Where exactly is our data going?”
That question has quietly killed more enterprise AI roadmaps than any technical failure.
For organizations in healthcare, financial services, defense, and consulting, it’s not a formality, it’s the single deciding factor between an AI initiative that scales and one that gets buried in compliance reviews for eighteen months.
This guide is for the teams who’ve decided the answer matters. Here’s how enterprises are actually deploying private AI, what it takes, what it costs, what to watch out for, and how to move from pilot to production without losing control of your data along the way.
First, Why Is Everyone Suddenly Talking About Private AI?
Because public AI tools broke their trust.
According to Stanford’s 2025 AI Index, 78% of organizations used AI in 2024, up from 55% the year before. Adoption doubled. But so did the problems:
- AI-related incidents jumped 56.4% in 2024, spanning data leaks, bias incidents, and regulatory failures
- 53% of organizations cite data privacy as their #1 concern with AI agents, above cost and integration complexity
- Only 25% of companies have moved 40%+ of their AI pilots into production, per Deloitte’s 2026 State of AI report
The gap between “we use AI” and “we use AI at scale, securely, in production” — that’s where most enterprises are stuck right now. Private AI deployment is how serious organizations are closing it.
What “Private AI” Actually Means (And What It Doesn’t)
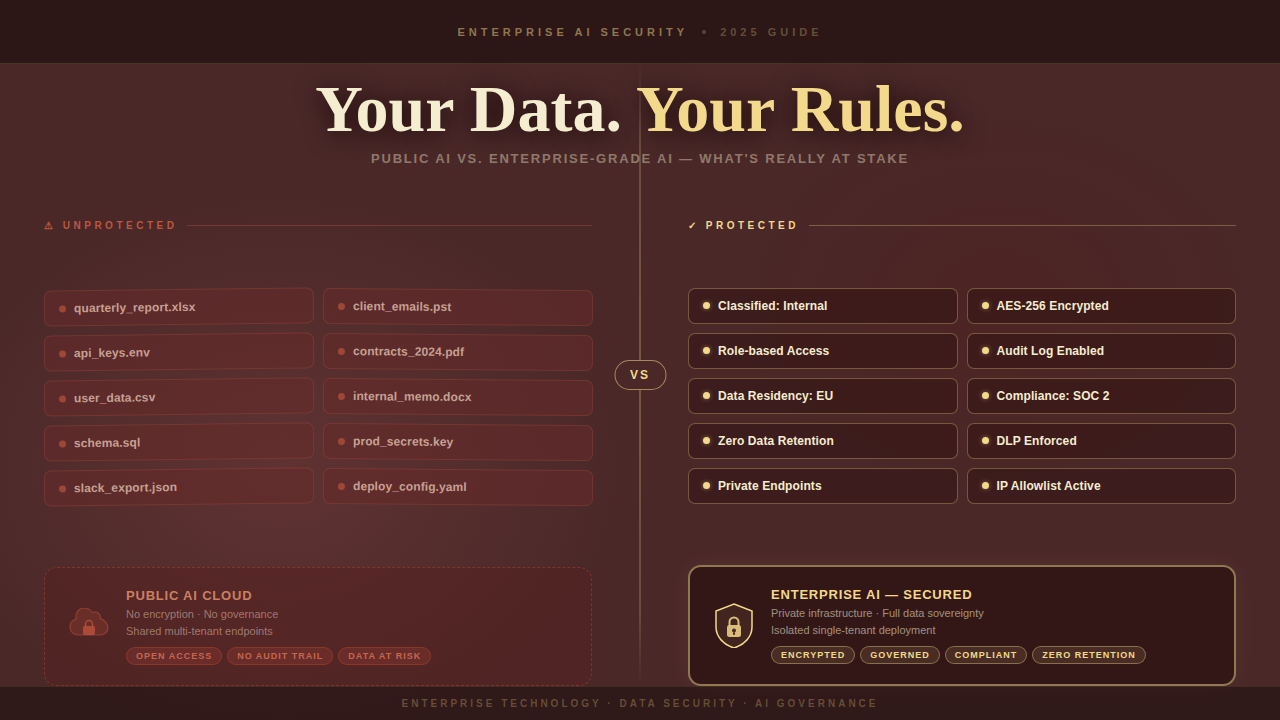
Private AI is not a product. It’s an architectural posture.
At its core, it means: your data never leaves your environment. The model runs on infrastructure you control, whether on-premises, in a dedicated private cloud, or inside your own VPC. No third-party servers processing your documents. No external privacy policy governing what happens to your most sensitive context.
Here’s how deployment models compare:
| Model | Data Control | Compliance Fit | Cost Structure | Best For |
| Public Cloud API | Low data sent externally | Limited | Variable / per-token | Prototyping, low-risk tasks |
| Private On-Premises | Full data never leaves | High fully auditable | Higher upfront, lower at scale | Regulated industries, sensitive IP |
| Private Cloud (VPC) | High isolated tenant | High configurable | Moderate, predictable | Scalable enterprise workloads |
| Hybrid | Tiered by sensitivity | Moderate to high | Optimized per workload | Enterprises needing flexibility |
Most mature enterprises don’t pick one and stick to it. They run a tiered architecture sensitive workloads go private, low-risk tasks go managed cloud. The key is knowing which workload belongs where before you deploy, not after.
The Compliance Map: Which Regulations Are Actually Forcing the Conversation?
Across regulated industries, private AI isn’t a preference, it’s a requirement. Here’s what the landscape looks like:
- GDPR EU citizen data often cannot be processed on US-based servers by default. Most public AI providers route through US infrastructure. Europe has issued €5.65 billion in GDPR fines since 2018 — enforcement is very real.
- HIPAA Feeding Protected Health Information into a public LLM without a signed Business Associate Agreement is a direct violation. BAAs are non-negotiable, and most public API endpoints don’t qualify.
- CMMC / NIST 800-171 Controlled Unclassified Information must stay within authorized system boundaries. Any third-party endpoint in the data path expands the compliance boundary and requires separate authorization.
- EU AI Act (fully effective August 2026) High-risk AI applications, recruitment, critical infrastructure, law enforcement, must now include risk assessments, activity logs, and human oversight mechanisms. Non-compliance: fines up to 7% of global annual turnover.
- SOC 2 / ISO 27001 Enterprise customers are requiring evidence of data isolation before signing vendor contracts. That means complete audit trails, something shared public APIs rarely provide out of the box.
The pattern: 68% of privacy professionals now handle AI governance alongside traditional compliance work. Regulators want evidence of controls, not policy documents.
The 4-Layer Architecture of Private AI That Actually Holds Up

Private AI isn’t just about where the model lives. It’s an end-to-end design question. Organizations deploying it successfully are building across four layers:
- Layer 1: Isolated Inference The model runs inside infrastructure you control. No query leaves your environment. Whether on-premises hardware or a private VPC, the inference boundary is yours to define and defend.
- Layer 2: Data Sovereignty All training data, retrieval context, and conversation history stays within your jurisdiction. This is what makes compliance certifications like HIPAA and CMMC possible, and what makes audit trails credible.
- Layer 3: Model Agnosticism You’re not locked into a single provider. As better models emerge, you can switch. This matters operationally: the best model for legal document review may not be the best model for financial summarization. The architecture should support both.
- Layer 4: Governed Pipelines Outputs are logged, auditable, and routed through human-in-the-loop checkpoints where regulation or risk demands it. Only 1 in 5 companies currently has mature governance of autonomous AI agents, per Deloitte, this layer is where most organizations are underbuilt.
“Doesn’t Private AI Mean Worse Performance?” No. Here’s Why.
This was a fair concern in 2022. It hasn’t been accurate for a while.
Stanford HAI reports that the cost of GPT-3.5-level inference dropped over 280-fold between late 2022 and 2024, driven by hardware efficiency gains and the rise of compact, purpose-built models. What once demanded massive cloud infrastructure now runs on hardware an enterprise can own.
The open-source model ecosystem accelerated this further. More than 50% of organizations now use open-source AI technologies, and among tech companies that figure rises to 72%. Models in the 7–20B parameter range, fine-tuned on domain-specific data, regularly outperform earlier general-purpose cloud LLMs on specialized tasks.
What this means practically: A financial services firm fine-tuning a compliance model on its own transaction data, running inference on its own infrastructure, can outperform a generic cloud LLM on its specific workflows, and never touch a third-party server.
Common Questions From Enterprise Teams
Q: How long does a full private AI deployment take?
For a mid-size enterprise with existing infrastructure, a production-ready deployment typically takes 3–6 months, covering infrastructure setup, model selection and fine-tuning, system integration, and governance implementation. Proof-of-concept environments can be running in weeks. The bottleneck is almost never the model, it’s data classification and access control design.
Q: Is it really more cost-effective than a public API?
At small scale: no. Public APIs win on upfront cost. At enterprise scale, continuous high-volume usage, sensitive workloads, regulatory overhead, private deployment typically delivers better economics. Predictable infrastructure costs replace variable per-token charges. You also avoid the ongoing cost of managing third-party data processing agreements, which has real legal overhead of its own.
Q: Can we still use GPT-4 or Claude models?
Some providers offer options between fully public and fully private, like Azure OpenAI Service or Anthropic’s enterprise API with data processing agreements.
These provide contractual protections and tenant isolation, but not on-premises control. For true air-gapped deployment, you’re looking at open-weight models (Llama, Mistral, Falcon) running on your own infrastructure. Many enterprises run both in parallel, open-weight models for the most sensitive workloads, hosted proprietary models for everything else.
Q: What about agentic AI, can autonomous workflows run in a private setup?
Yes, and this is arguably where private deployment matters most. Agentic AI needs access to internal systems, proprietary databases, and sensitive documents to function. Running the inference layer privately means the agent’s full context, every document it retrieves, every action it takes — stays within your security boundary. Only 23% of organizations are currently scaling AI agents in production, per McKinsey. The ones doing it successfully have the governance infrastructure to support it.
The 5-Step Adoption Roadmap
The biggest mistake enterprises make is treating private AI as an all-or-nothing infrastructure overhaul. It isn’t. The organizations making real progress are taking a tiered, workload-first approach.
Step 1: Classify your data before you touch your infrastructure
Not all data needs the same level of isolation. Identify what’s regulated (PHI, CUI, PII), what’s proprietary IP, and what’s genuinely low-risk. This single step determines which workloads go where, what compliance controls apply, and what your infrastructure actually needs to support. Skip it, and you’ll over-engineer some things and under-protect others.
Step 2: Match deployment tier to workload sensitivity
| Workload Type | Examples | Recommended Tier |
| Low sensitivity | Internal FAQs, summarization, drafting | Managed cloud AI |
| Medium sensitivity | HR data, customer comms, code review | Private cloud / VPC |
| High sensitivity | Legal docs, clinical notes, financial models, M&A | On-premises / air-gapped |
You don’t need one answer for every workload. A tiered approach is both more cost-efficient and more defensible to your compliance team.
Step 3: Pick infrastructure that matches your compliance posture
- On-premises, maximum control, air-gap capability, highest upfront cost
- Private VPC (AWS, Azure, GCP), scale with tenant isolation, faster deployment
- Hybrid — flexibility across workload types, optimized cost
The MLOps layer matters as much as the hardware, platforms for orchestration, monitoring, and model management are what turn a private deployment into a governed, auditable system.
Step 4: Build governance before you need it
Model logging. Output auditing. Role-based access controls. Human-in-the-loop checkpoints for high-stakes decisions. These are far easier to build into a system before it’s in production than after. Deloitte identifies AI governance infrastructure as the #1 differentiator between organizations that scale AI and those that don’t.
Step 5: Close the skills gap deliberately
Deloitte identifies the AI skills gap as the top barrier to enterprise AI integration. The model is the easy part. Training the teams that operate, monitor, govern, and trust it appropriately is where most organizations underinvest. Budget for it explicitly — it is not optional at scale.
Already Running Public AI Pilots? There’s a Faster Path to Private.
Most enterprises don’t start private. They start with ChatGPT or a cloud API, get promising results, and then hit the wall when Legal or IT asks about data controls. That transition, from a promising public AI pilot to a governed private deployment, is where a lot of good work stalls.
This is exactly the problem LyzrGPT is built to solve.

LyzrGPT is a private, enterprise-grade AI platform that deploys inside your own environment, your VPC or on-premises infrastructure, so your data never leaves your control. It’s designed specifically for organizations that want ChatGPT-level capability without the data sovereignty tradeoffs.
Here’s what makes it practically useful for enterprise adoption:

- Model Agnostic Switch between OpenAI, Anthropic Claude, Gemini, Groq, AWS Bedrock, and open-source models, all from a single interface. No vendor lock-in. No re-architecting when a better model ships.
- VPC / On-Premises Deployment Deploy on your own infrastructure with SOC 2 and GDPR-compliant architecture. Your data doesn’t move. Your compliance posture doesn’t change.
- 1,000+ Pre-Built Agents Pre-built AI agents for sales outreach, customer support, HR, finance, legal review, and more. Teams go from deployment to productive workflows in days, not months.
- Memory Pocket Import your existing conversation history from ChatGPT, Claude, or Gemini. Continuity across models, without starting from scratch.
- Responsible AI Guardrails Automated PII redaction, audit trails, and configurable access controls built into the platform, not bolted on after the fact.
- Built for the organizations that couldn’t use public tools LyzrGPT is already deployed at organizations like Prophet, WTW, and Accenture, enterprises where data governance isn’t a checkbox, it’s a prerequisite.
If your team has run a public AI pilot and knows it needs to move to a governed private environment, LyzrGPT is worth a look.
The Bottom Line: Private AI Is a Compounding Advantage
Here’s what doesn’t get said enough about private AI deployment: it’s not just risk mitigation. It’s a moat.
Every public API integration your competitors build, they can replicate tomorrow. The model is the same. The capability ceiling is the same. The data flowing through it is still someone else’s infrastructure.
Private AI is different. The model fine-tuned on your proprietary data. The agent with access to your internal knowledge base. The compliance posture that lets you deploy in verticals your competitors can’t touch. None of that is replicable with an API key.
Two-thirds of organizations remain stuck in pilot purgatory, per McKinsey’s 2025 State of AI survey — running experiments that never reach production. The organizations breaking out of that pattern share one thing: they answered the data question first.
Where is your data going? Who controls it? Can you prove it?
Answer those questions with infrastructure, and the rest of the AI roadmap tends to move much faster.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here