Table of Contents
ToggleLast quarter, a Fortune 500 financial services company quietly canceled three AI agent projects mid-deployment.
Not because the agents weren’t smart, they were. Not because the technology failed, it worked. They pulled the plug because nobody could explain why the agents were doing what they were doing. Regulators asked questions. The team had no answers. The agents were brilliant. They were also invisible.
This is the quiet crisis spreading across enterprise AI right now. And if you’re scaling AI agents , or planning to, AI agent observability for enterprises is the conversation your team needs to be having before your next deployment, not after.
What Even Is AI Agent Observability for Enterprises?
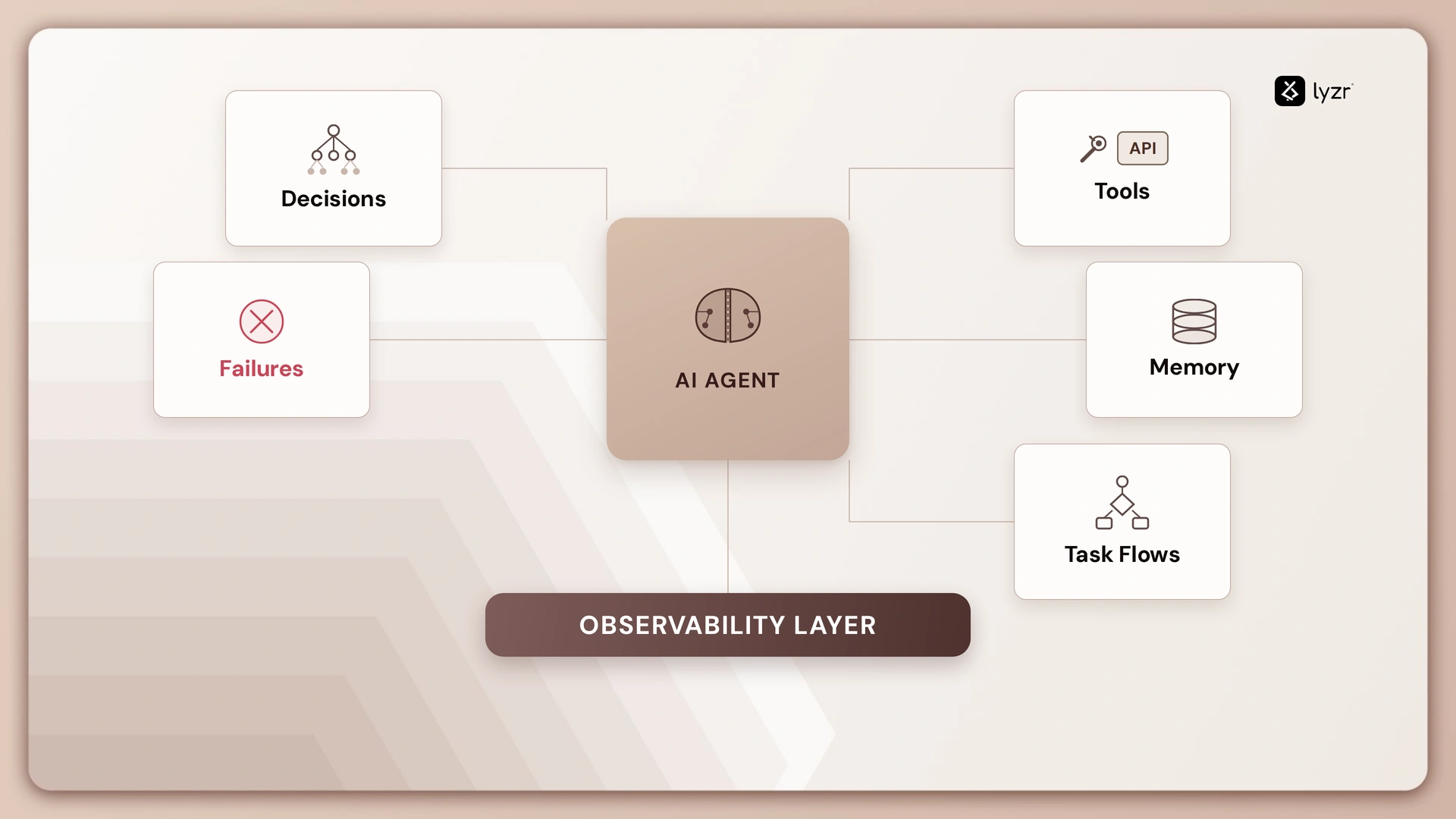
Traditional monitoring tells you if something broke. AI agent observability tells you why an agent made a decision — before it breaks something.
When your agents are handling IT tickets, processing invoices, managing customer escalations, or executing trades, each one is making dozens of micro-decisions every minute. Observability is the infrastructure that makes those decisions visible, traceable, and auditable — in real time.
Here’s what it actually captures:
| Signal | What It Tells You |
| Reasoning traces | The full thought chain behind every agent action |
| Tool invocations | Which APIs, databases, and systems the agent touched |
| LLM call spans | Exactly what prompt went in and what came out |
| Decision paths | Why the agent chose action A over action B |
| Output evaluations | Whether the response was accurate, safe, and compliant |
Without it, you’re running a business process in a black box. In 2026, that’s not just a technical risk — it’s a governance and compliance liability.
Quick Self-Assessment: How Observable Are Your Agents Right Now?
Take 60 seconds. Answer honestly — Yes, No, or Not Sure.
| # | Question | Your Answer |
| 1 | Can you trace exactly what reasoning steps your agent took on any given request from last week? | |
| 2 | If an agent gave a wrong answer to a customer today, could you find the root cause within 30 minutes? | |
| 3 | Do you have real-time alerts when an agent’s output starts drifting from expected behavior? | |
| 4 | Can your compliance team pull a complete audit trail for any agent decision — without involving engineering? | |
| 5 | If you swapped your underlying LLM tomorrow, would you know immediately how it affected output quality? |
How to read your score:
| Score | What It Means | Your Priority |
| 4–5 Yes | Ahead of 85% of enterprises | Focus on multi-agent orchestration visibility |
| 2–3 Yes | Partial observability — flying with some instruments, not all | One production incident away from a scramble |
| 0–1 Yes | Monitoring gap, not an observability strategy | Good news: you’re catching this early enough to fix it right |
Keep your score in mind as you read the rest — it’ll make the recommendations land differently.
Why “We Have Datadog” Is Not the Answer
This is the most common objection. And it’s understandable. Here’s why it misses the point entirely.
| Dimension | Traditional Monitoring | AI Agent Observability |
| What it watches | System health — latency, uptime, error rates | Agent cognition — reasoning, decisions, tool use |
| How failures show up | Crashes, stack traces, downtime alerts | Drift, hallucination, subtly wrong decisions |
| Response time | Catches failures after they happen | Designed to catch deviation before damage is done |
| Compliance support | Logs that something failed | Traces that explain why a decision was made |
| Multi-agent support | Per-service monitoring in silos | End-to-end trace stitching across agent handoffs |
AI agents don’t fail the way traditional software fails. A token-level hallucination inside an agent’s reasoning chain can propagate silently through a multi-step workflow and surface three steps later as a compliance breach. A subtle prompt change can trigger an entirely different decision tree. Bias can enter through a data retrieval step that no one is watching.
By the time traditional monitoring catches the anomaly, the damage is already done. AI agent observability for enterprises doesn’t just watch the container. It watches the cognition.
The 5 Layers Every Enterprise Observability Stack Needs
Most teams think about observability as a single thing. It’s not. It’s a stack — and missing even one layer creates blind spots.
| Layer | What It Does | Why It’s Non-Negotiable |
| End-to-End Trace Stitching | Connects input parsing, LLM calls, tool invocations, and output formatting into one coherent trace | You need to know not just that a database query happened, but which reasoning step triggered it |
| Real-Time Reasoning Visibility | Live insight into tool selection, intermediate outputs, and agent intent during execution | Critical in multi-agent workflows where one agent’s output becomes another’s input |
| Semantic Drift & Hallucination Detection | Flags when agent output deviates from expected behavior before it reaches a user | Agents don’t fail loudly — they drift quietly |
| Governance-Grade Audit Trails | Every action logged with policy, user, model, and context metadata | When the auditor asks “why did the agent do that on March 14th at 3:47 PM?” — you need a clean answer |
| Business Context Mapping | Connects agent behavior to your actual data policies, governance rules, and compliance requirements | The gap between “the agent did this” and “the agent did this because…” is the gap between monitoring and observability |
The Multi-Agent Problem Nobody Is Talking About Enough
Single agents are relatively straightforward to monitor. The real AI agent observability challenge , and the one most enterprises are about to run headfirst into, is multi-agent orchestration.
When Agent A hands off to Agent B, which triggers Agent C while also calling a third-party API, the failure surface multiplies fast:
| Failure Type | How It Happens | Why It’s Hard to Catch |
| Cascading tool failures | One agent’s bad API call becomes another agent’s corrupt input | No single agent “errors out” — the workflow just quietly degrades |
| Reasoning propagation | A hallucination in Agent A is interpreted as valid context by Agent B | By the time it surfaces, the origin is buried three layers deep |
| Policy boundary violations | An agent accesses a system it shouldn’t, triggered by a handoff from a governed agent | Standard access logs won’t show the reasoning chain that led there |
| Latency compounding | Slow performance in one agent creates a queue backup across the entire workflow | Impossible to diagnose without per-span timing across the full trace |
Quick gut-check: How many AI agents does your organization have running in production right now? If it’s more than a handful — and you can’t trace their last 100 decisions — you have an observability gap that’s growing every day.
What’s at Stake by Industry
AI agent observability for enterprises isn’t a one-size-fits-all concern. The compliance stakes and failure consequences vary dramatically by sector.
| Industry | What Agents Are Doing | The Observability Risk If You Get It Wrong |
| Financial Services & Banking | Credit decisions, KYC processing, transaction flagging | Unexplainable decisions trigger regulatory action; EU AI Act and SEC guidance make auditability legally mandatory |
| Healthcare | Prior authorizations, triage routing, clinical documentation | A hallucinated drug interaction check that slips through is a patient safety liability, not a tech bug |
| Insurance | Claims processing, fraud detection, policy renewals | One biased pattern in fraud logic can systematically impact thousands of claims before anyone notices |
| Enterprise IT & Operations | IT ticketing, infrastructure provisioning, incident response | A misconfigured agent can cascade changes across systems faster than any human can intervene |
The Compliance Dimension Everyone Is Underestimating
The EU AI Act is already in force. The SEC is scrutinizing AI-driven financial decisions. HIPAA doesn’t pause because an AI agent made the call instead of a human.
Observability is no longer just an engineering concern. It is a board-level risk management tool.
| Compliance Question | Where the Answer Lives |
| “Can we prove our AI agent didn’t discriminate in this underwriting decision?” | Your observability layer’s reasoning traces |
| “Did our agents operate within policy boundaries during last quarter’s audit window?” | Your governance-grade audit trail |
| “Which model version was running when this output was generated?” | Your LLM call span metadata |
| “Who authorized this agent to access this data source?” | Your access and permission logs |
The enterprises building traces, evaluations, and governance guardrails into agent architecture from day one are the ones that will scale without regulatory landmines. The ones bolting it on after the fact are the ones writing incident reports.
Your Checklist: What to Look for in an AI Agent Observability Platform
Every vendor claims “full observability.” Here’s how to cut through the noise.
| Requirement | The Right Answer | The Red Flag |
| Framework compatibility | Sits above LangChain, CrewAI, AutoGen, custom stacks without forcing a rewrite | “You’ll need to migrate your agents to our framework” |
| Monitoring approach | Real-time trace visibility during execution | Batch log analysis only — tells you what happened yesterday |
| Hallucination & PII handling | Native to the pipeline, checked on every output | An optional add-on module |
| Governance model | Access controls, audit trails, and policy enforcement as first-class features | Governance treated as a reporting layer |
| Deployment options | VPC or on-premise deployment available for regulated environments | Cloud-only with no data residency guarantees |
| Multi-agent support | Unified trace stitching across agent handoffs and frameworks | Per-agent monitoring in separate dashboards |
Which One Are You? Find Your Scenario, Find Your Next Step
Pick the description that sounds most like your team right now:
| Your Situation | What It Means | Your Next Step |
| Still in pilot phase — agents aren’t in production yet | You’re in the best possible position. Observability is 10x easier to build in than bolt on. | Define your trace requirements and governance guardrails before first deployment. Ask: what does a “good” agent run look like, and how will you know when one goes wrong? |
| A few agents in production, monitoring is mostly manual | Most common — and most dangerous — spot. Manual monitoring doesn’t scale past 5–10 agents. | Pick one agent, instrument it fully, and use it as your observability template before scaling further. |
| Dozens of agents running, not sure what half of them are doing | Agent sprawl. More common than anyone admits publicly. | Start with discovery — knowing what agents are running, where, and with access to what — before thinking about trace-level observability. |
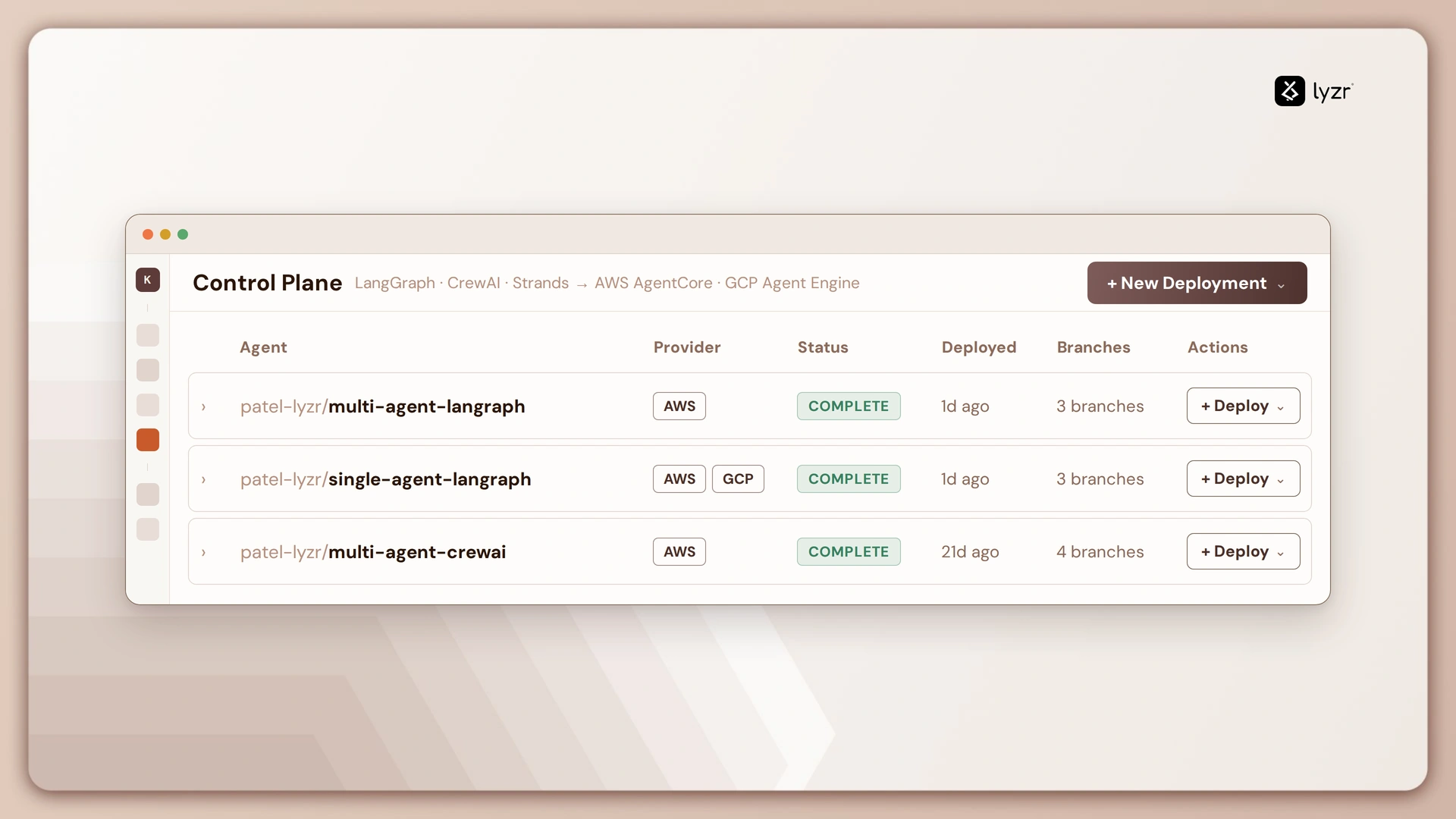
| Observability in place, but fragmented across teams and frameworks | Solving the right problem, but blind spots will appear at every multi-agent handoff. | Move to a unified control plane that stitches traces across frameworks so nothing disappears between dashboards. |
How Lyzr.ai Is Solving AI Agent Observability for Enterprises
Most observability tools stop at the trace. They’ll show you what happened. Enterprise AI teams need to know why it happened, whether it was compliant, and how to fix it — all from a single control plane. That’s the gap Lyzr.ai is built to close.
| Lyzr Capability | What It Does | Why It Matters for Enterprises |
| Control plane architecture | Sits above LangChain, CrewAI, AutoGen, Agentforce, and custom stacks — no migration required | Your existing agents stay where they are; governance and observability layer on top |
| Real-time full trace | Every action logged, every decision traceable across single and multi-agent workflows | No gaps between agent handoffs — the full execution chain is always visible |
| Native hallucination & PII guard | Every output checked before it reaches a user, built into the core architecture | Not a bolt-on — catches issues at the pipeline level, not after the fact |
| Agent Simulation Engine | Runs up to 10,000 simulations against real-world conditions before an agent goes live | Agents are battle-tested before production, not in production |
| Flexible deployment | VPC or fully on-premise with zero data egress framework | Your data never leaves your environment — non-negotiable for regulated industries |
Accenture has invested in Lyzr specifically to bring this approach to banking and insurance — two of the most demanding AI agent observability environments in the world.
One Lyzr customer achieved a 95% reduction in agent response time across markets, attributing it directly to the observability and control capabilities that let their team actually trust their agents in production.
The Question Your Team Should Be Asking This Week
Not “should we invest in AI agent observability for enterprises?” That question is settled.
The question is: “Are we building observability in from the start, or are we going to be the team retrofitting it after our first production incident?”
The enterprises winning at agentic AI right now are treating observability as infrastructure — as foundational as the network, as non-negotiable as authentication, as strategic as the models themselves.
The ones who aren’t? Some of them are in that 40% Gartner is watching get canceled.
Where Do You Go From Here?
If you’re in the early stages of agent deployment, now is the time to architect AI agent observability into your enterprise stack — not after you’ve shipped 20 agents to production and need to reverse-engineer tracing into each one.
If you’re already running agents in production without a unified observability layer, you have a gap that’s growing every day.
Lyzr’s team works with enterprise AI teams specifically on this problem — from first deployment to governing hundreds of concurrent agents across multi-agent workflows. If that’s the stage you’re at, it’s worth booking a conversation.
Because the agents are already running. The only question is whether you’re watching.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here