Table of Contents
ToggleAI agents are getting smarter, but they are also running into a growing problem: too much context.
Every workflow generates conversations, documents, API responses, logs, and memory states that agents are expected to process continuously. At small scale, this works. But as systems grow, context becomes noisy, expensive, and difficult to manage.
That is where Autonomous Context Compression comes in.
Instead of feeding everything into the model, AI systems learn how to preserve only the information that actually matters for reasoning and decision-making.
The context problem starts small, then grows everywhere
Most AI systems today rely on context windows to operate.
But enterprise AI systems rarely deal with one clean conversation. They deal with constant streams of information arriving from multiple systems at the same time.
| Enterprise Workflow | Context Sources |
| Customer support | Chats, CRM data, tickets |
| Finance operations | Transactions, approvals |
| IT operations | Logs, alerts |
| Multi-agent systems | Shared memory, task states |
At first, teams usually solve this by increasing context size or expanding retrieval pipelines.
That works for a while.
Then systems start slowing down, token usage increases, and agents begin missing important details buried inside large context chains.
The issue is no longer about access to information.
It becomes a problem of relevance management.
So what exactly is Autonomous Context Compression?
Autonomous Context Compression is the process where AI systems intelligently reduce, summarize, prioritize, and restructure context without human intervention.
Instead of sending every piece of information into the model every time, the system continuously decides:
- What matters right now
- What should be summarized
- What should stay in long-term memory
- What can safely be ignored
- What needs to be retrieved later
Think about how humans operate in long-running projects.
Nobody rereads every email, meeting note, and document from day one before making a decision. People naturally carry forward only the information that remains relevant.
Autonomous compression tries to bring that same behavior into AI systems.
Why “more context” stops working after a point
For a long time, the industry treated larger context windows as the answer.
Bigger models. More tokens. More retrieval.
But larger context windows alone do not solve memory quality.
In many cases, they introduce entirely new problems.
| Traditional Approach | Result |
| Bigger context windows | Higher costs |
| Full conversation history | Slower responses |
| Large retrieval outputs | More noise |
| Static memory systems | Buried information |
The deeper issue is simple:
Not all context deserves equal importance.
An AI agent may process thousands of signals during a workflow, but only a fraction actually impacts the next decision.
Without filtering and prioritization, relevant information gets diluted inside unnecessary data.
The real shift is happening quietly
The conversation around AI infrastructure is changing.
Earlier, most teams focused on:
- Prompt engineering
- Model quality
- Retrieval pipelines
- Tool integrations
Now the focus is shifting toward something more operational:
How do AI systems maintain reliable memory over time?
Because once agents move beyond demos and start running inside real enterprise workflows, memory handling becomes one of the biggest bottlenecks.
Long-running systems create:
- Massive chat histories
- Repeated retrieval outputs
- Duplicate memory states
- Irrelevant context accumulation
- Rising inference costs
And this is exactly where Autonomous Context Compression becomes critical.
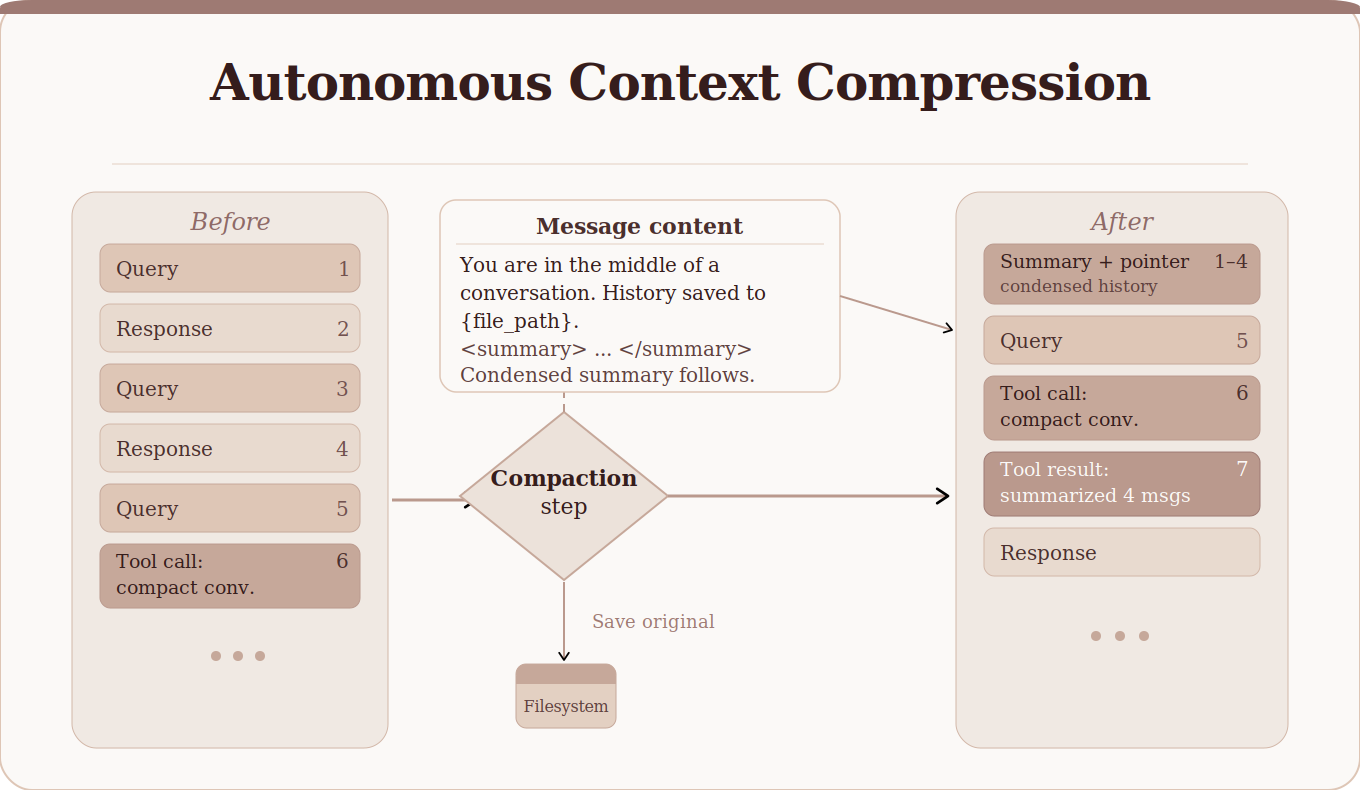
What actually happens inside a compression pipeline?
Autonomous compression is not a single feature.
It is usually a layered process running continuously during agent execution.
A simplified pipeline often looks like this:
| Stage | What Happens |
| Context ingestion | Data enters from tools, chats, APIs |
| Relevance scoring | Important information gets prioritized |
| Summarization | Key insights get condensed |
| Memory classification | Data stored as short-term or long-term memory |
| Retrieval optimization | Relevant memory indexed for future use |
This allows agents to maintain continuity without carrying unnecessary information into every interaction.
Instead of overwhelming the model with raw data, the system continuously reshapes memory into something usable.
Multi-agent systems make the challenge even bigger
Single-agent workflows already struggle with context overload.
Multi-agent systems multiply the problem.
Now agents are constantly sharing:
- Plans
- Task states
- Intermediate outputs
- Tool results
- Shared memory updates
Without compression, communication overhead grows rapidly.
| Without Compression | With Compression |
| Raw memory overload | Prioritized context |
| Higher latency | Faster responses |
| Repeated information | Optimized memory |
| Rising token usage | Lower costs |
This becomes especially important in enterprise environments where multiple agents collaborate across departments, workflows, or systems.
Because eventually, scalability stops being about model intelligence alone.
It becomes about memory efficiency.
Why enterprises are suddenly paying attention
The shift toward production-grade AI systems is exposing the hidden cost of unmanaged context.
Enterprises are realizing that large-scale AI deployments are not just model problems.
They are infrastructure problems.
Especially in industries where workflows generate massive amounts of information every day.
| Industry | Why It Matters |
| Banking | Large compliance histories |
| Healthcare | Long patient records |
| Legal | Document-heavy workflows |
| Government | High-volume procedural data |
In these environments, AI systems must preserve continuity across long-running workflows without constantly reprocessing everything from scratch.
That requires intelligent memory handling.
Not just larger models.
Compression is not just summarization
This is where many discussions become oversimplified.
Summarization is only one part of Autonomous Context Compression.
True compression systems also handle:
- Context prioritization
- Semantic preservation
- Memory lifecycle management
- Retrieval optimization
- Dynamic reconstruction
The goal is not simply making information shorter.
The goal is making information more useful for reasoning.
Because removing the wrong detail can completely change how an AI agent behaves.
A good compression system preserves:
- Intent
- Dependencies
- Constraints
- Decisions
- Temporal relevance
While still reducing the overall context load.
That balance is what makes the problem difficult — and valuable.
The next generation of AI systems will compete on memory efficiency
The AI industry spent the last few years competing on model capability.
The next phase will focus heavily on operational scalability.
Because the question is changing.
Earlier, teams asked: “Can the agent answer correctly?”
Now enterprises are asking: “Can the agent operate reliably for months across large workflows?”
That requires:
- Better context orchestration
- Smarter memory systems
- Efficient retrieval
- Long-running continuity
- Lower inference overhead
Autonomous Context Compression sits directly at the center of that shift.
Final thoughts
AI systems are entering a phase where scale is no longer theoretical.
Agents are now expected to operate across massive workflows filled with conversations, documents, APIs, and constantly evolving memory states.
And raw context accumulation is starting to hit practical limits.
Autonomous Context Compression changes the approach entirely.
Instead of forcing models to process everything all the time, AI systems learn how to preserve relevance, reduce noise, and maintain continuity intelligently.
The result is not just lower token usage.
It is more reliable AI systems that can scale without collapsing under their own memory load.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here