As AI agents take on decision-support roles across compliance, operations, and customer-facing workflows, accuracy becomes more than a quality metric, it becomes a responsibility. Hallucinations, off-policy responses, or contextually incorrect answers can introduce risk, erode trust, and create compliance exposure.
The Hallucination Manager in Lyzr Agent Studio is designed to address this challenge directly. Rather than relying on prompts alone, Lyzr allows teams to configure Responsible AI controls at the platform level, ensuring agents operate within defined boundaries while remaining useful and responsive.
This blog explains how the Hallucination Manager works, the controls it provides, and how those controls work together to reduce hallucinations without overly constraining agent behavior.
Why Hallucination Control Needs Configuration, Not Prompts
Most hallucination issues stem from a lack of explicit constraints. When models are left to infer rules, policies, or domain boundaries implicitly, they tend to fill gaps with plausible-sounding but incorrect information.
Prompt-based mitigation helps, but it has limits:
- Prompts are interpreted probabilistically
- Long conversations dilute instruction strength
- Policy enforcement becomes inconsistent across agents
The Hallucination Manager addresses this by separating rules from prompts and making them first-class configuration elements. These controls are enforced consistently, regardless of how conversations evolve.
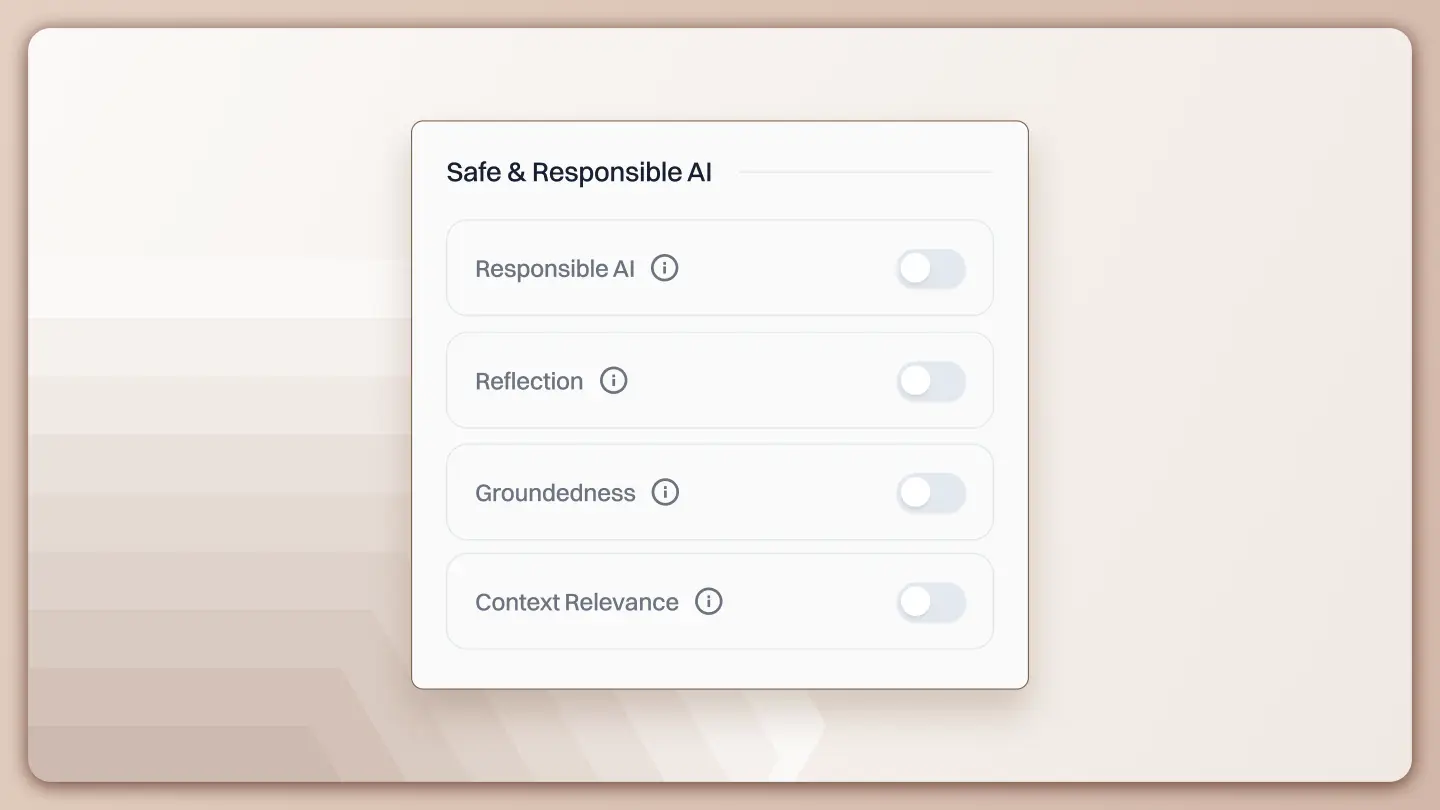
Responsible AI Controls in Lyzr
The Hallucination Manager brings multiple safety mechanisms together under a single configuration surface. Each control targets a different failure mode, and they are designed to work in combination rather than isolation.

At a high level, the controls focus on:
- Defining what the agent must know and respect
- Validating outputs before they are returned
- Limiting how freely the model can speculate
- Ensuring only relevant context is considered
Each of these is configurable directly from the UI.
Adding Responsible AI Facts
Responsible AI Facts are the foundation of hallucination control. They define the non-negotiable rules and domain truths the agent must adhere to.
These facts act as guardrails that inform the model about constraints it cannot ignore, even when user input pushes in a different direction.
When adding a Responsible AI Fact, two elements are required.
- Policy Name: This is a descriptive label that identifies the rule. It should clearly indicate the purpose of the policy, such as regulatory compliance, brand alignment, or domain boundaries.
- Content: This is the actual policy text or factual rule. Examples include legal guidelines, compliance requirements, operational constraints, or tone and language rules
Once added, these facts become part of the agent’s reasoning framework. They are not optional hints; they are treated as authoritative references that shape how responses are generated.
Responsible AI Facts are especially useful in scenarios where agents operate in regulated or high-risk domains, where creative freedom must always be secondary to correctness.
Enabling Reflection
Reflection introduces a validation step into the response generation process. Instead of returning the first generated answer, the model evaluates its own output against the configured Responsible AI Facts.

Reflection works as a self-check mechanism:
- The model generates a response
- It evaluates whether the response violates any defined facts
- If inconsistencies are detected, the response is revised
This additional step helps catch subtle hallucinations that are not obvious at generation time but become apparent when compared against explicit rules.
Reflection can be toggled on or off depending on the use case. In environments where accuracy and policy adherence are critical, enabling reflection significantly improves response reliability with minimal impact on response flow.
Configuring Groundedness
Groundedness controls how strictly the model must base its responses on provided sources, facts, or retrieved context.

Rather than being a binary setting, groundedness is controlled through a slider that ranges from 0 to 1.
- At lower values, the model has more freedom to infer and reason creatively
- At higher values, the model is constrained to rely heavily on supplied facts and context
A fully grounded setting forces the agent to stay close to known information, reducing speculative responses. This is particularly important in compliance, legal, and policy-driven workflows.
Choosing the right groundedness value is about balance. Over-constraining the model can make responses rigid or overly cautious, while under-constraining increases the risk of hallucinations. Lyzr allows teams to tune this behavior based on the agent’s role rather than applying a one-size-fits-all rule.
Setting Context Relevance
Context relevance determines how much of the available context the model considers when generating a response. This control is designed to prevent the model from relying on outdated, irrelevant, or tangential information.
As conversations grow longer or involve multiple topics, older context can become misleading. Without constraints, models may reference information that is no longer applicable.
By enforcing context relevance:
- Only pertinent context windows are considered
- Off-topic drift is reduced
- Responses remain aligned with the current user intent
This is especially important for long-running sessions or agents that handle multiple workflows within the same conversation.
How These Controls Work Together
Each control in the Hallucination Manager addresses a specific risk, but their real strength comes from how they combine.
Responsible AI Facts define what must be true.
Reflection checks whether responses respect those truths.
Groundedness controls how tightly responses adhere to known information.
Context relevance ensures only appropriate information is considered.
Together, they form a layered defense against hallucinations. Instead of relying on post-hoc detection or manual review, hallucination risk is reduced proactively at generation time.
Practical Impact on Agent Behavior
When configured correctly, the Hallucination Manager changes how agents behave in subtle but important ways.
Responses become:
- More consistent across sessions
- Less speculative when information is missing
- More transparent about uncertainty
- Better aligned with organizational rules
Instead of confidently incorrect answers, agents are more likely to stay within defined boundaries or acknowledge limitations.
This is particularly valuable in enterprise environments, where trust in agent output is often a prerequisite for adoption.
Closing Perspective
Hallucination control cannot be an afterthought, especially as AI agents are embedded into critical workflows. It requires explicit configuration, clear rules, and built-in validation mechanisms.
The Hallucination Manager in Lyzr Agent Studio provides these capabilities through UI-driven Responsible AI controls. By combining factual guardrails, reflection, groundedness tuning, and context relevance, teams can deploy agents that are not only capable, but also accountable.
Rather than limiting what agents can do, these controls define how agents should behave—ensuring reliability without sacrificing usefulness.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here