The Year Everyone Got an AI Budget, and Nobody Could Agree on a Model
Cast your mind back to 2023. AI budgets were suddenly real.
Boards were asking CIOs about strategy. Executives were passing around ChatGPT demos in slide decks. The message was simple and urgent: pick a model, get started, show results.
So that’s what enterprises did. They picked one.
Some picked GPT-4. Others went with Claude. A few went deep on Gemini. Contracts were signed. Integrations were built. Internal tools were wrapped around whichever frontier model the vendor had the best relationship with.
It felt decisive. It felt modern. For about six months, it even felt like the right call.
Then reality showed up.
The Single-Model Trap
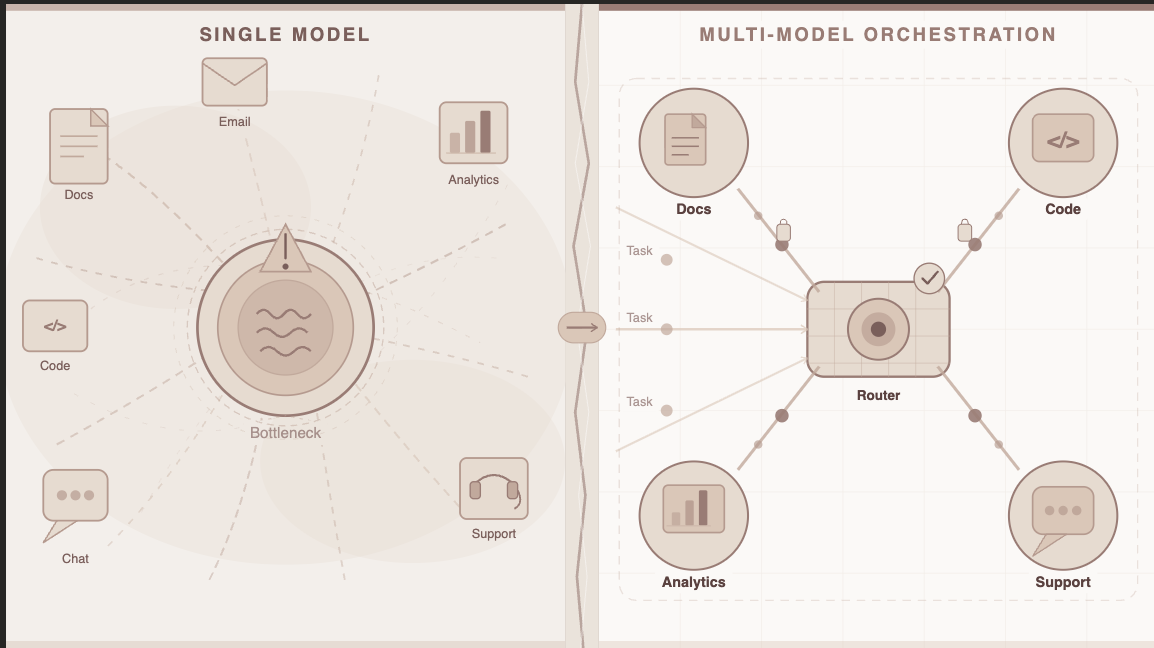
Here’s something no AI vendor was putting in their sales deck: no single model is the best tool for every job. Not GPT. Not Claude. Not Gemini. Not any of them.
Each model has genuine strengths — and genuine blind spots. Enterprise teams discovered this the hard way:
- The model they’d integrated for legal document review was mediocre at writing customer emails
- The model that excelled at code generation struggled with nuanced financial analysis
- The model running their customer service bot was overkill (and over-budget) for simple FAQ queries
- The “best” model today became mid-tier six months later when a competitor shipped something better
Meanwhile, the cost structure made the problem worse. Enterprise AI contracts tend to be per-seat, per-model, and tied to a single vendor. Switching models meant switching contracts, renegotiating terms, rebuilding integrations, and retraining teams.
So organizations were stuck. Not with bad AI, with inflexible AI. And there’s a big difference.
By 2026, the global enterprise LLM market is estimated at $8.19 billion — yet most of that spend is still concentrated on single-vendor deployments that don’t reflect how enterprise workloads actually vary.
Why Enterprise Work Doesn’t Fit One Model
To understand why multi-LLM is inevitable, you have to think about what enterprise work actually looks like on any given day.
A mid-size financial services firm running AI in 2026 might need:
| Task | Ideal Model Characteristics | Cost Priority |
| Drafting client-facing emails | Fluent, tone-aware, fast | Low cost per query |
| Reviewing loan applications | Precise, structured reasoning | Moderate |
| Monitoring regulatory filings | Deep document comprehension | Can be batched overnight |
| Customer support triage | Low latency, reliable, multilingual | High volume = cost-sensitive |
| Executive strategy memos | Nuanced, long-context, high quality | Occasional, cost less sensitive |
| Code review for internal tools | Code-optimized reasoning model | Dev team, moderate volume |
You already see the problem. These six use cases need six different profiles. Some need speed. Some need depth. Some need to be cheap because they run thousands of times per day. Some are fine spending more because they run twice a week for the CEO.
Trying to cover all of this with one model means either overpaying on low-stakes queries or underperforming on high-stakes ones. Neither is acceptable when you’re answerable to a CFO.
The Model Race Nobody Can Win — Alone

Here’s another dynamic accelerating the multi-LLM shift: the pace of the model race itself.
In 2023, GPT-4 felt like a plateau. Eighteen months later, we had GPT-5.2, Claude Opus 4.6, Gemini 3 Pro, Llama 4, Mistral Medium 3, DeepSeek V3.2, and Grok 4.1, all competing at the frontier, all with meaningfully different strengths and pricing.
The lead time for a “best model” went from years to months. Sometimes weeks.
For an enterprise locked into one model, this creates a real strategic problem. Your AI stack is only as good as the model it runs on. If you’ve hardwired your workflows to GPT-4 and the best reasoning model for your use case is now something else — you’re still paying for GPT-4 contracts, still rebuilding on top of legacy integrations, still explaining to your board why your AI isn’t keeping pace.
Vendor lock-in stopped being a procurement annoyance and became a competitive liability.
The organizations that figured this out earliest started asking a different question. Not “which model should we use?” but “how do we build an AI layer that isn’t beholden to any single model?”
That question is where multi-LLM platforms were born.
What a Multi-LLM Platform Actually Does
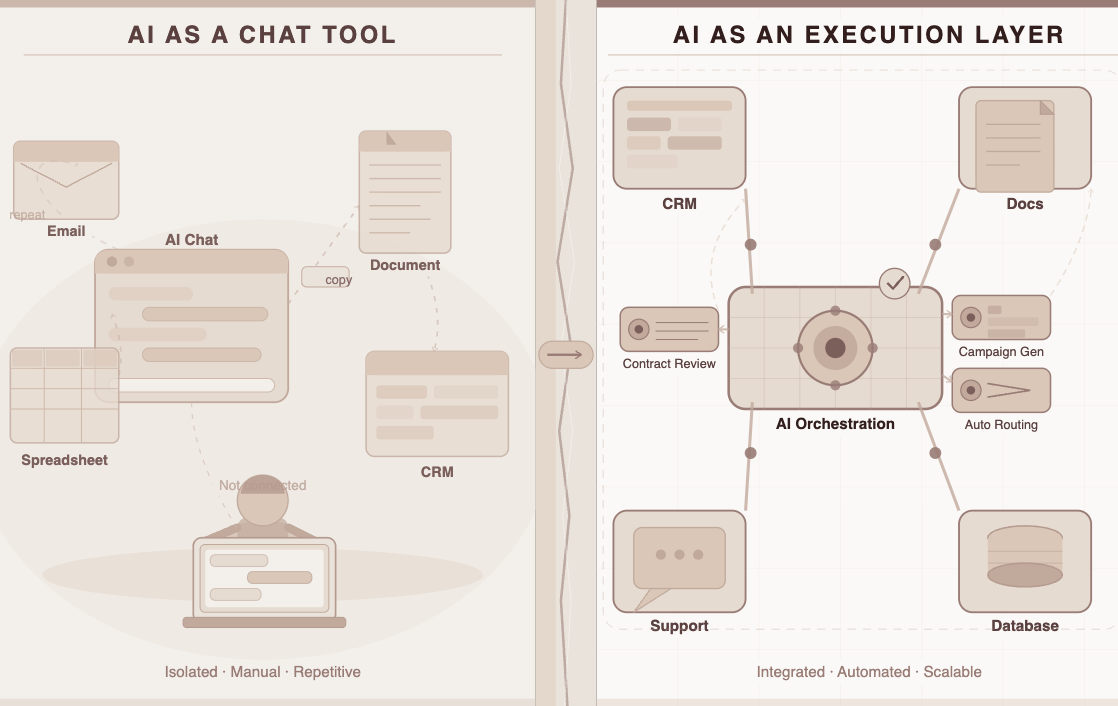
The concept is elegant once you see it. Instead of choosing a single model and building everything around it, a multi-LLM platform acts as the intelligent layer between your enterprise and the entire model ecosystem.
It does four things a single-model deployment simply can’t:
1. Routes each query to the right model automatically Not every question needs a frontier model. A multi-LLM platform classifies the task and routes it intelligently — complex reasoning to a high-capability model, routine queries to a faster, cheaper one. The output quality goes up. The cost per query goes down.
2. Lets you swap models without rebuilding workflows When a better model ships — and they ship constantly now — you update the routing layer. Your workflows don’t change. Your integrations don’t break. You adopt the best of what’s available without a migration project.
3. Eliminates dependence on any single vendor’s roadmap If OpenAI changes pricing, you have options. If a particular model degrades in a new update, you route around it. If your preferred vendor has an outage, failover is automatic. Resilience becomes a feature of the platform, not a lucky accident.
4. Gives you a single governance layer across all models This is the part that matters most for regulated industries. Instead of managing compliance, access controls, and audit trails separately for each model you use, a multi-LLM platform unifies governance. One policy engine. One audit log. One place where your CISO can see everything.
The Industries Driving the Shift
Multi-LLM adoption isn’t uniform across sectors. The industries leading the charge are, predictably, the ones where the cost of getting it wrong is highest.
🏦 Banking & Financial Services
Banks deal with a genuinely extreme range of AI tasks — from real-time fraud detection (low latency, high volume) to generating quarterly risk reports (long-context, high precision). No single model serves both well at acceptable cost. Meanwhile, regulatory requirements mean governance can’t be an afterthought. Multi-LLM platforms with private deployment and immutable audit trails have become a compliance necessity, not a technical luxury.
🏥 Healthcare
Clinical documentation, patient triage, diagnostic support, insurance pre-authorization — each of these use cases has completely different performance requirements and radically different data sensitivity levels. A multi-LLM layer lets healthcare organizations match the right model to each task while keeping all data within a HIPAA-compliant private infrastructure.
⚖️ Legal & Insurance
Contract review, litigation clause extraction, policy underwriting, compliance monitoring — these are document-heavy, precision-critical workflows where model quality directly affects legal and financial exposure. AI agents for insurance built on multi-LLM platforms are now showing measurably better outcomes than single-model alternatives because they can assign each stage of a complex workflow to the model best suited for it.
🛒 Enterprise SaaS & Operations
At scale, even a few cents’ difference in cost per query multiplied by millions of daily interactions becomes a massive budget line. Multi-LLM platforms with intelligent routing have given enterprise SaaS teams a path to significantly reduce AI operating costs while maintaining output quality — by routing low-complexity queries to efficient, cheaper models rather than burning frontier model budget on tasks that don’t need it.
The Catch: Most Platforms Don’t Actually Deliver This
The idea of multi-LLM is sound. The market for solutions claiming to deliver it is noisy.
Most “multi-model” products on the market today are really just model switchers — they let you manually select between GPT and Claude in a dropdown. There’s no intelligent routing. No unified governance. No private deployment. No consumption-based pricing. No enterprise-grade memory. Just a wrapper with more options in the menu.
For an enterprise that needs to actually build AI into production workflows — not just experiment in a chat interface — the gap between what’s marketed and what’s delivered is stark.
The real checklist for a genuine multi-LLM enterprise platform looks like this:
| Capability | What It Actually Means |
| Model-Agnostic Architecture | Any model can be swapped in or out without rebuilding workflows |
| Intelligent Query Routing | Platform automatically assigns queries to the optimal model per task |
| Private Deployment | Runs entirely within your VPC or on-premise — no data leaves your environment |
| Unified Governance | One RBAC, one audit log, one PII redaction layer across all models |
| Consumption-Based Pricing | You pay for what’s used — not per seat, not per model license |
| Persistent Enterprise Memory | Context carries across sessions and model switches securely |
| Pre-Built Agentic Workflows | Ready-to-run agents for real business functions, not just a chat interface |
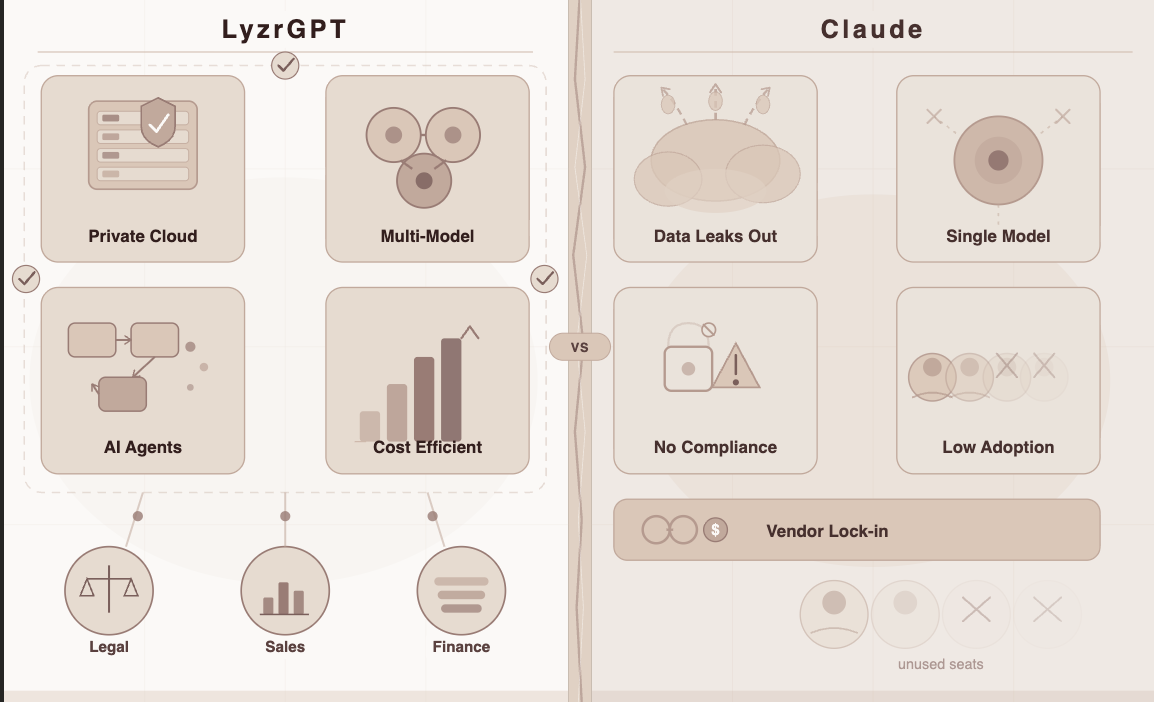
Very few platforms check all of these. One that does is LyzrGPT.
Enter LyzrGPT: Multi-LLM Done Right for Enterprise
“The future of enterprise AI isn’t choosing the right model. It’s building a layer that makes the right choice for you — every time.”
LyzrGPT, launched by Lyzr AI in March 2026, was built to be exactly this layer. It’s a private, model-agnostic enterprise AI platform that doesn’t just give you access to multiple models — it actively manages them on your behalf, within your environment, under your governance rules.
Here’s how it maps to everything we’ve discussed:
1. True Model-Agnosticism — Not Just a Dropdown
LyzrGPT runs on GPT-4, Claude, Gemini, Llama, and others — and can switch between them mid-conversation based on what the task demands. More importantly, it routes automatically. You set the rules; LyzrGPT handles the decisions.
When a new frontier model ships, you don’t rebuild. You update the routing config. Your workflows stay intact, your costs stay optimized, and your vendor lock-in stays at zero.
2. Private by Default — Not Private as an Add-On
Most multi-model platforms still run on shared SaaS infrastructure. LyzrGPT deploys entirely within your own VPC or on-premise environment. Your prompts, your data, your outputs — none of it ever leaves your perimeter.
For the banking, healthcare, insurance, and legal teams we discussed earlier: this isn’t a feature. It’s the prerequisite.
3. Pre-Built Agents That Actually Do the Routing Work
LyzrGPT doesn’t just expose models. It ships with a library of purpose-built enterprise agents that are already wired to use the right model for the right task:
| Team | What the Agents Do |
| Sales | AI SDR (Jazon) handles outreach, Deal Nurturer follows the pipeline — each using the optimal model for personalization vs. analysis |
| Banking | Loan origination, KYC, regulatory monitoring — precision-critical agents grounded in your private data |
| Insurance | Claims processing, policy underwriting, litigation extraction — document-heavy workflows matched to the best document model available |
| HR | AI Hiring Assistant screens, schedules, and surfaces candidates without your data touching any external server |
These aren’t prompt templates. They’re production-ready workflows that embed multi-LLM intelligence from day one.
Consumption Pricing That Scales With How You Actually Use AI
Because LyzrGPT routes intelligently, you only pay for what each query actually needs. Low-complexity queries go to efficient models. Complex reasoning goes to frontier models. Your AI bill reflects real usage — not a flat rate per seat that punishes you for having 5,000 employees with wildly different AI usage patterns.
One Governance Layer for All of It
Across every model, every agent, every team — LyzrGPT provides:
| Governance Feature | Why It Matters for Multi-LLM |
| Role-Based Access Control | Different teams access different models and agents based on their role |
| Immutable Audit Logs | Every query, every model used, every output — fully logged and traceable |
| Automatic PII Redaction | Personal data stripped at the infrastructure level before it reaches any model |
| Configurable Guardrails | You set the rules once — they apply across every model in the platform |
| RAG-Grounded Responses | Every answer tied to your verified internal documents, not the public internet |
This is what makes multi-LLM viable for regulated industries — not just the model flexibility, but the ability to govern it all from one place.
The Numbers Behind the Shift
To get a sense of how fast this is moving:
| Metric | Figure |
| Global enterprise LLM market in 2026 | $8.19 billion |
| Projected CAGR through 2034 | 27.45% |
| Enterprises expected to automate 50%+ of network ops with AI by 2026 | 30% |
| LLM apps expected to include bias mitigation by 2026 | 70%+ |
| Enterprises treating hyperautomation as a strategic priority | ~90% |
The market isn’t waiting. The question isn’t whether enterprises will adopt multi-LLM platforms — it’s whether they’ll build the right governance, privacy, and flexibility into the layer when they do.
So What Should Your Enterprise Do Right Now?
The playbook is clearer than it might feel:
1. Stop evaluating AI by model. Evaluate by platform. The model you need today will not be the model you need in 18 months. The platform you build your AI strategy around will be.
2. Demand private deployment. If your data is leaving your environment to power your AI workflows, you have a compliance risk you may not have fully mapped yet. Private deployment is not a premium feature — it’s a baseline requirement.
3. Break free from per-seat pricing. As AI adoption grows inside your organization, you want costs to track usage — not headcount. Consumption-based pricing is how you scale AI without a budget crisis every quarter.
4. Build with agents, not just prompts. The value of multi-LLM platforms compounds when you wire them to real workflows. Pre-built agentic workflows that already know which model to use, when to switch, and how to stay compliant are how you go from AI experimentation to AI operations.
5. Unify your governance now, before scale makes it hard. It’s far easier to implement responsible AI guardrails, audit trails, and RBAC before you have 40 AI workflows running across 8 departments. Do it now, while the architecture is still malleable.
The Bottom Line
The single-model era of enterprise AI is ending — not because any model failed, but because the enterprise world is complex enough that no single model was ever going to be enough.
Multi-LLM platforms are what happens when AI matures past the proof-of-concept phase and gets serious about production. They give enterprises the flexibility to use the best tool for each job, the governance to do it safely, and the economics to do it at scale.
LyzrGPT is where that future is available today. Private. Model-agnostic. Agent-ready. Governed from the ground up.
The organizations that build on the right layer now won’t just have better AI. They’ll have AI that gets better over time — without rebuilding from scratch every time the model leaderboard changes.
👉 See What a Multi-LLM Enterprise Platform Looks Like
One platform. Every model. Your data, your environment, your rules.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here