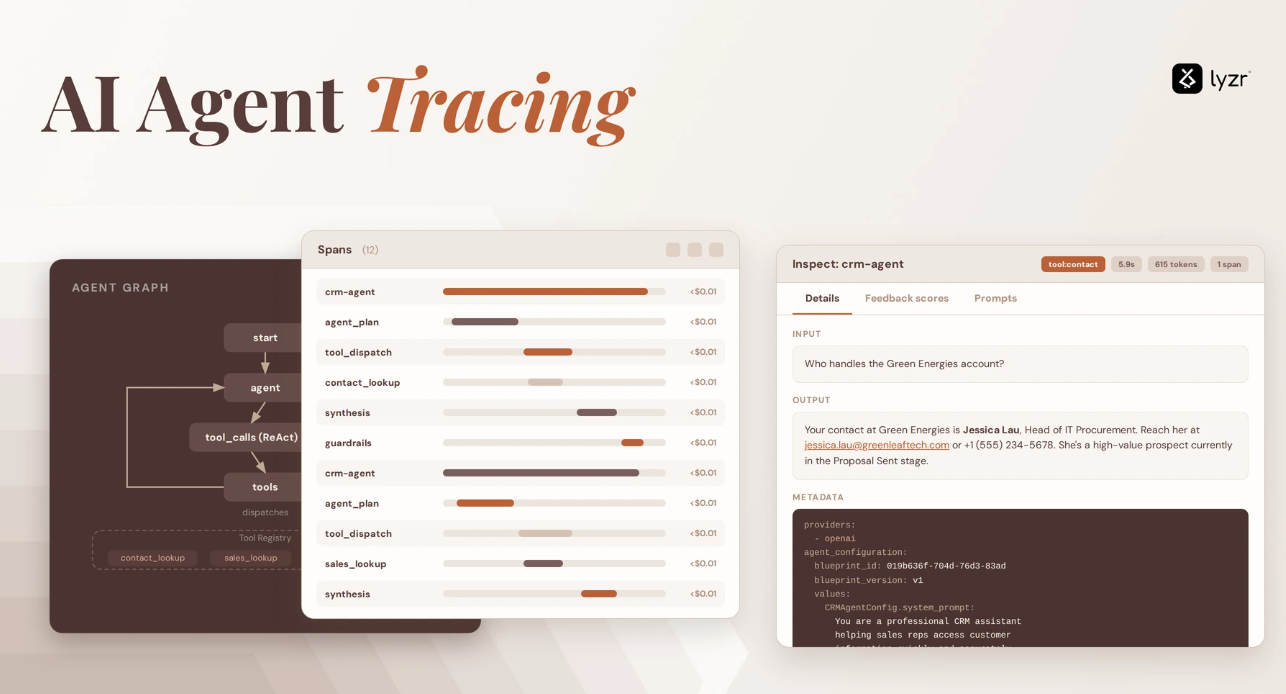
Testing AI agents through real conversations, not single prompts
Most AI evaluation methods follow a simple pattern: a prompt goes in, the AI produces a response, and the output is evaluated.
This approach works well for quick checks. Teams can verify whether an AI agent can answer a question correctly, summarize a document, or generate a response that meets basic expectations.
But real interactions with AI agents rarely happen in a single prompt.
Users ask follow-up questions.
They add more context. They refine instructions. Conversations evolve across multiple exchanges, and the quality of the final outcome depends on how well the AI handles the entire interaction.
This is where Multi-Turn Evaluation in the Simulation Engine becomes important. Instead of evaluating one isolated response, it evaluates how an AI agent performs across a complete conversation.
Why Single-Turn Evaluation Isn’t Enough
Traditional evaluation focuses on a simple flow.
| Step | Interaction |
| User Prompt | “Summarize this PRD.” |
| AI Response | Generates a summary |
| Evaluation | Check accuracy or completeness |
This structure works for straightforward tasks, but enterprise workflows are rarely this simple.
Consider a more realistic interaction:
| Turn | Conversation |
| 1 | User asks the AI to review a PRD |
| 2 | AI asks for the document |
| 3 | User provides additional context |
| 4 | AI analyzes the document and identifies gaps |
| 5 | User asks follow-up questions |
| 6 | AI suggests improvements or timeline adjustments |
Here, the success of the interaction depends on how well the AI handles multiple conversational turns.
Single-turn testing cannot capture whether the AI remembers earlier context, reasons across steps, or produces a meaningful final outcome.
What Multi-Turn Evaluation Does
Multi-Turn Evaluation introduces a more realistic way to test AI agents.
Instead of evaluating isolated prompts, the Simulation Engine runs a complete conversation scenario between a user and an AI agent.
Each simulation typically includes three key components:
| Component | Purpose |
| Scenario | Defines the situation being tested |
| Persona | Defines the type of user interacting with the agent |
| Conversation Flow | A sequence of exchanges between the user and the AI |
As the simulation progresses, the engine evaluates how the agent responds at every step. It checks whether the AI maintains context, follows instructions correctly, and builds logical responses across multiple turns.
By the end of the simulation, the evaluation reflects the overall quality of the interaction, rather than a single response.
Running Multi-Turn Simulations in Lyzr Agent Studio
Multi-Turn Evaluation is available directly within Lyzr Agent Studio as part of the Simulation Engine.

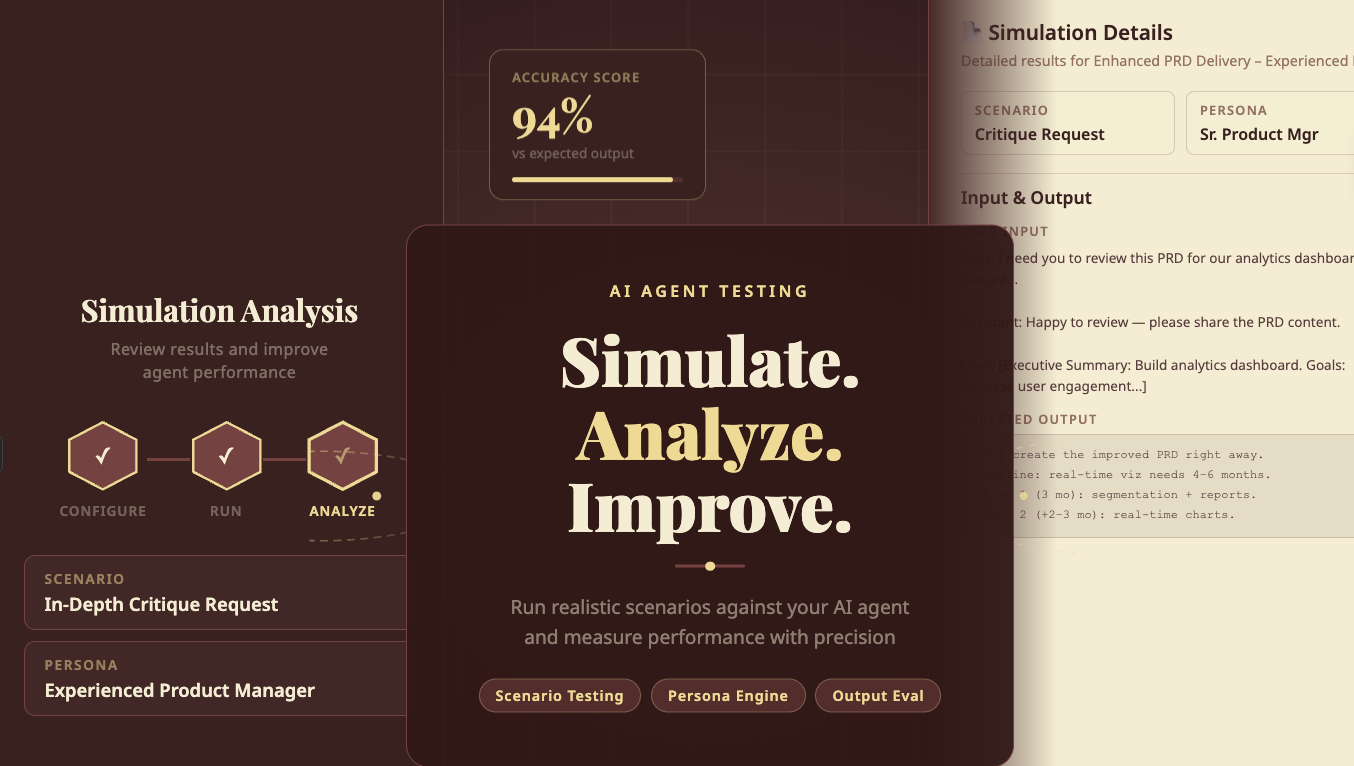
Inside the studio, teams can configure a simulation by defining the scenario, selecting a persona, and running a conversation between the user and the AI agent. The system captures the entire interaction, including the prompts, responses, and the expected outcome.
A typical simulation setup inside the studio looks like this:
| Configuration Element | Example |
| Scenario | In-depth critique request |
| Persona | Experienced Product Manager |
| Task | Review and improve a PRD |
| Expected Outcome | Provide a structured critique and improvement plan |
Once configured, the Simulation Engine runs the interaction and generates a detailed log of how the agent handled each conversational turn.
Example: Simulating a PRD Review in the Studio

To understand how this works in practice, consider a simulation where a product manager asks the AI agent to review a Product Requirements Document for a new analytics dashboard.
Inside the simulation interface, the scenario is defined as an in-depth critique request, with the persona set as an experienced product manager preparing a document for an executive review.
The conversation then unfolds step by step.
First, the user asks the agent to review the PRD and identify what needs improvement. The agent responds by requesting the document and explaining the criteria it will use for analysis.
Once the PRD content is provided, the agent analyzes the document and identifies several gaps. For example, it may point out:
- Missing user personas
- Vague problem statements
- Undefined success metrics
- Lack of technical considerations
- Absence of a risk assessment
The interaction continues when the user asks whether the proposed three-month timeline for the project is realistic.
At this point, the AI must refer back to the earlier conversation. It considers the complexity of features such as segmentation, real-time data visualization, and custom report generation before evaluating the feasibility of the timeline.
A well-performing agent might suggest a phased delivery plan, where foundational capabilities are delivered first and more complex features are added in later phases.
The Simulation Engine records each step of this interaction, allowing teams to review exactly how the agent handled the conversation.
What the Simulation Engine Evaluates
During a multi-turn simulation, the engine evaluates several aspects of agent behavior.
| Evaluation Dimension | What It Measures |
| Context Retention | Whether the AI remembers earlier parts of the conversation |
| Instruction Adherence | Whether the AI follows the user’s request correctly |
| Reasoning Across Turns | Whether later responses build logically on earlier ones |
| Response Relevance | Whether the responses stay aligned with the task |
| Outcome Completeness | Whether the conversation ends with a useful result |
These dimensions provide a clearer understanding of how an AI agent performs when conversations become more complex.
Why Multi-Turn Evaluation Matters for Enterprise AI
Enterprise AI agents are increasingly used across workflows such as document analysis, customer support, product planning, and internal knowledge queries.
In most of these scenarios, interactions unfold across multiple conversational turns.
Without multi-turn evaluation, teams risk deploying agents that perform well on simple prompts but struggle with extended conversations.
Common issues include:
| Potential Issue | Example |
| Context Loss | Agent forgets details mentioned earlier |
| Repetition | Agent repeats generic responses |
| Weak Reasoning | Responses fail to build on previous turns |
| Incomplete Outputs | The final response does not fully address the task |
Multi-Turn Evaluation helps identify these issues early, allowing teams to refine prompts and improve agent behavior before deployment.
From Prompt Testing to Conversation Testing
As AI agents take on more complex enterprise workflows, their capabilities continue to grow. Users expect agents to ask clarifying questions, interpret context, analyze complex inputs, and guide tasks toward meaningful outcomes.
Evaluating these capabilities requires more than checking whether a single prompt was answered correctly.
Multi-Turn Evaluation shifts AI testing from response-level evaluation to conversation-level evaluation.
Instead of asking, “Did the AI answer this question correctly?” teams can now evaluate, “Did the AI handle the entire interaction effectively?”
For AI agents designed to support real workflows, that shift in evaluation makes a meaningful difference.
Multi-Turn Evaluation is available within Lyzr Agent Studio, where teams can design agents, simulate real conversations, and evaluate performance before deployment.
If the goal is to build agents that work reliably in real enterprise scenarios, the next step is simple: start building and testing them inside the studio.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here