An AI agent without a lifecycle plan is a liability waiting to happen.
Agent Lifecycle Management (ALM) is the end-to-end process of designing, deploying, monitoring, updating, and eventually retiring an AI agent.
It’s about ensuring the agent performs reliably and safely throughout its entire operational existence.
From the moment it is built.
To the moment it is shut down.
The simplest way to grasp this?
Think about managing an employee’s career at a company.
You hire them (deploy).
You train them and give them the right tools (configure/fine-tune).
You assign them tasks (runtime execution).
You review their performance (monitoring/evaluation).
You promote or retrain them when their role changes (updates/versioning).
And eventually, they retire when their job is no longer needed.
Agent Lifecycle Management is exactly that-but for your AI agents.
Neglecting this process means you’re not just deploying an asset. You’re deploying an unmanaged risk that can drift from its purpose, fail silently, and burn through resources without accountability.
What is Agent Lifecycle Management in AI?
It’s the formal discipline for governing an AI agent from creation to deletion.
ALM provides the structure and control needed to manage an autonomous system.
It moves beyond just building a cool prototype.
It’s about operationalizing that agent in a responsible, scalable, and predictable way.
This framework covers everything:
Initial goal setting and tool selection.
Secure deployment into a live environment.
Continuous performance tracking against business KPIs.
Controlled updates to its model, tools, or instructions.
And a planned, clean decommissioning process.
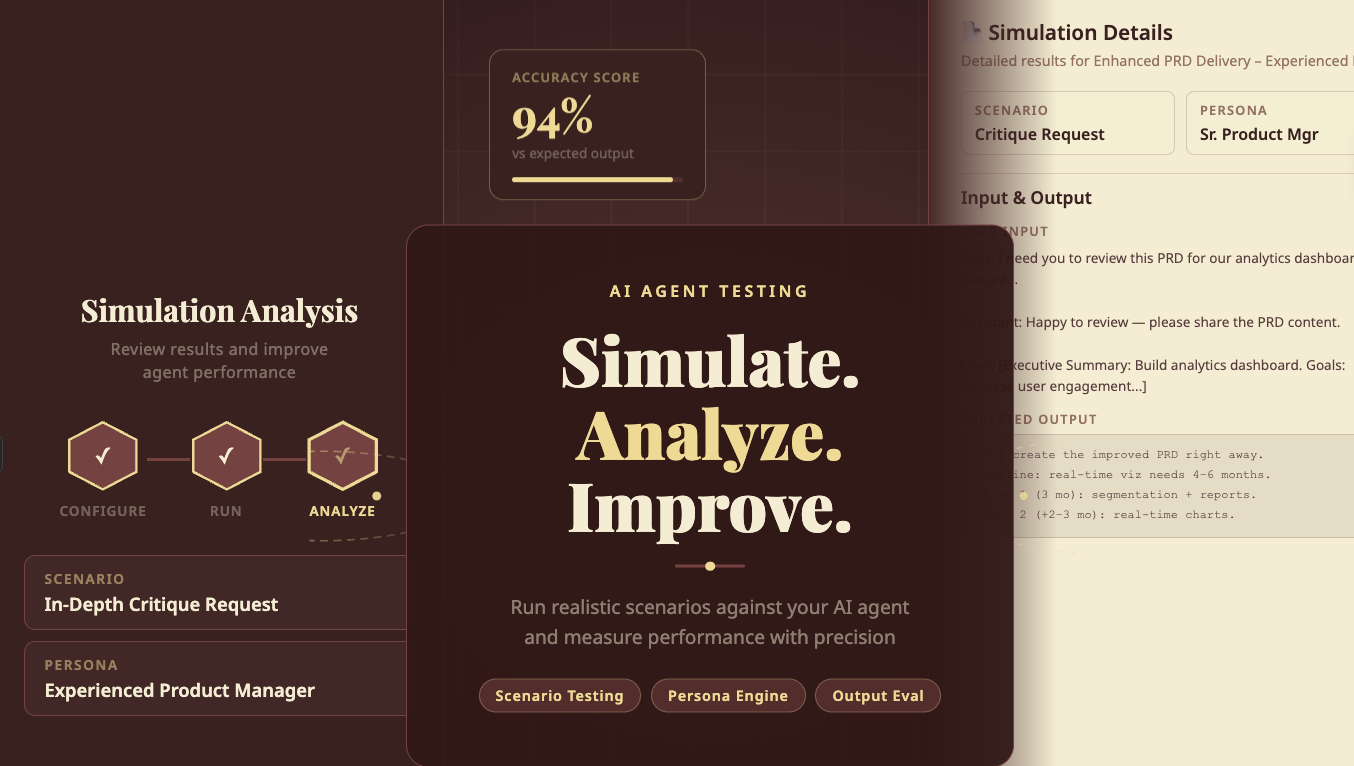
What are the key stages of an AI agent’s lifecycle?
The lifecycle follows a clear, logical progression, much like traditional software, but with unique AI-specific considerations at each stage.
1. Design & Development
This is the blueprint phase.
You define the agent’s purpose, goals, and constraints.
You select the core LLM, assign specific tools (APIs, databases), and craft its initial instructions or persona.
2. Deployment & Provisioning
Here, the agent goes live.
This involves configuring its environment, granting necessary permissions, and integrating it into existing workflows.
For example, deploying a customer service agent into a live chat system like Intercom.
3. Monitoring & Observability
Once active, you must watch it.
This isn’t just about server uptime.
It’s about tracking its behavior, decision-making paths, tool usage, token consumption, and task success rates.
Are its answers accurate? Is it failing silently? Is it costing too much?
4. Update & Maintenance
Agents are not static.
Based on monitoring data, you’ll need to update them.
This could mean fine-tuning the model, updating its instructions, swapping out a tool for a better one, or rolling back to a previous version if performance degrades.
5. Retirement & Deprecation
No agent lasts forever.
When a business process changes, a better agent is developed, or it simply becomes obsolete, it needs to be retired.
This final stage involves revoking its access, archiving its operational data, and ensuring a clean shutdown without disrupting systems.
How does Agent Lifecycle Management differ from MLOps?
This is a crucial distinction. They are related but solve different problems.
MLOps (Machine Learning Operations) is about the model.
Its lifecycle is: data collection -> training -> versioning -> deploying the model as an endpoint.
It ensures the ML model itself is robust and performant.
Agent Lifecycle Management (ALM) is about the entire agentic system.
The model is just one component.
ALM governs the agent’s:
- Goals and instructions.
- Persistent memory and state.
- Interactions with external tools and APIs.
- Autonomous decision-making loops.
- Overall behavioral alignment.
You can have a perfectly healthy model (thanks to MLOps) inside a misaligned or failing agent. ALM manages the whole employee, not just their brain.
Similarly, ALM is not the same as Agent Orchestration.
Orchestration is about managing how multiple agents interact at runtime.
ALM is the bigger picture-governing each of those agents from birth to death.
Why is Agent Lifecycle Management important for enterprise AI deployments?
Without ALM, deploying agents in a business context is reckless.
It’s the framework that provides:
- Governance & Safety: ALM ensures you can track why an agent made a certain decision. It provides guardrails to prevent an agent from “drifting” away from its intended purpose, which is a major AI safety concern.
- Reliability & Consistency: Continuous monitoring and controlled versioning mean you can guarantee a certain level of performance. When Waymo updates its driving agents, it uses a rigorous ALM process to ensure the new version is safer than the last.
- Cost Control: Autonomous agents can consume huge amounts of tokens and compute resources. ALM includes monitoring for cost spikes and efficiency, preventing runaway expenses.
- Scalability: When you move from one agent to one thousand, you need a centralized system for managing their versions, permissions, and performance. ALM provides this control plane. Companies like ServiceNow and Salesforce use ALM to manage thousands of agents deployed across their customer base.
What technical mechanisms are used for Agent Lifecycle Management?
The core isn’t about general coding. It’s about robust evaluation and management harnesses built for AI.
This involves a specific stack of technologies:
- Agent State Management & Persistent Memory: To maintain context and learn over time, an agent’s memory (using vector stores like Pinecone or Weaviate) must be managed and versioned. If you update an agent, what happens to its “memories”? ALM protocols define this.
- Observability & Tracing Frameworks: You need to see how an agent thinks. Tools like LangSmith or Arize AI provide traces that show every step of an agent’s reasoning-the prompts, the tool calls, the outputs. This is essential for debugging and performance tuning at every lifecycle stage.
- Agent Versioning & Rollback Protocols: You don’t just push a new agent to production. ALM adapts CI/CD concepts for AI. This includes blue-green deployments (running two versions in parallel) and canary releases (testing a new agent on a small percentage of users). Rollbacks can be triggered automatically if key metrics like task success rate drop.
Quick Test: Can you spot the lifecycle stage?
Imagine you’re managing a fleet of AI agents. Where in the ALM process do these activities fall? Drag and drop them to the right stage.
Activities
- Defining the agent’s primary goal and authorized tools.
- Pushing the agent into the company’s live Slack channel.
- Noticing the agent’s API error rate has spiked by 20%.
- Updating the agent’s base model from GPT-4 to GPT-4o.
- Revoking the agent’s API keys because the project is finished.
Lifecycle Stages
- Design
- Deploy
- Monitor
- Update
- Retire
(Answers: 1-Design, 2-Deploy, 3-Monitor, 4-Update, 5-Retire)
Deep Dive FAQs
What happens to an AI agent’s memory and state during a version update in ALM?
This is a critical challenge. A good ALM strategy includes a “state migration” plan. For simple updates, the new version might inherit the old memory. For major changes, the old memory might be archived, and the new agent starts fresh to avoid behavioral conflicts.
How do you know when an AI agent needs to be retrained, updated, or retired?
Through constant monitoring against pre-defined KPIs. Key triggers include:
- Performance Degradation: The agent’s task success rate drops.
- Behavioral Drift: The agent starts responding in ways that are outside its intended alignment or persona.
- Business Change: The process the agent was built for no longer exists.
- New Technology: A new model or tool becomes available that offers a step-change in performance.
What is agent behavioral drift, and how does ALM prevent it?
Behavioral drift is when an agent’s outputs slowly change over time, even if its code hasn’t. This can happen due to shifts in the data it processes or subtle changes in underlying models. ALM prevents this through continuous automated testing and evaluation, where the agent’s responses are constantly compared against a “golden set” of correct examples.
How does ALM differ when managing a single agent vs. a multi-agent system?
It gets exponentially more complex. For multi-agent systems, ALM must also manage the lifecycle of the interactions between agents. This includes versioning communication protocols and monitoring the health of the entire swarm, not just the individual units.
What are the governance and compliance considerations in Agent Lifecycle Management?
Huge ones. ALM provides the audit trail. You need logs of every agent version, every major decision, and every manual override. For compliance in regulated industries like finance or healthcare, this non-repudiable record is a legal necessity.
How do canary deployments and shadow testing apply to AI agent rollouts?
- Canary Deployment: You roll out a new agent version to a small, specific user group (e.g., 5% of customers) and compare its performance against the old version before a full rollout.
- Shadow Testing: The new agent runs in parallel with the old one, processing real requests but not sending its responses to the user. Its decisions are logged and compared to the existing agent’s decisions to validate its performance safely.
What metrics define a ‘healthy’ AI agent across its lifecycle stages?
It’s a dashboard of metrics:
- Task Success Rate: Does it complete its job successfully?
- Latency: How fast does it respond?
- Cost Per Task: How many tokens/resources does it use?
- Tool Error Rate: How often do its API calls fail?
- Alignment Score: Does its behavior match its intended persona and instructions?
How does Agent Lifecycle Management integrate with existing DevOps or CI/CD pipelines?
It extends them. A DevOps pipeline for an agent includes new stages like “Automated Behavioral Evaluation” and “Shadow Mode Deployment.” The triggers for rollbacks aren’t just code failures but also dips in AI-specific performance metrics.
What is the role of human-in-the-loop (HITL) oversight in Agent Lifecycle Management?
It’s an essential safety and quality control layer. HITL can be used as an approval gate for high-stakes decisions an agent makes, a mechanism for users to correct agent mistakes, and a source of data for fine-tuning future agent versions.
How do platforms like Lyzr AI or LangChain simplify Agent Lifecycle Management for developers?
They provide the foundational infrastructure. Instead of building complex monitoring, versioning, and tracing systems from scratch, developers can use these platforms as a managed control plane. They offer the tools to design, deploy, and especially monitor agents, abstracting away the heavy lifting of ALM.
The future of business will be run by fleets of AI agents.
Agent Lifecycle Management is the discipline that will determine whether those fleets are productive assets or chaotic liabilities.
Did I miss a crucial point? Have a better analogy to make this stick? Let me know.