LLM Ops (Large Language Model Operations) is the set of practices, processes, and tools for efficiently developing, deploying, monitoring, and maintaining large language models in production environments. It adapts DevOps and MLOps principles specifically to the unique challenges of working with large language models.
Think of it like running a sophisticated restaurant kitchen that serves AI language models. A restaurant needs systems for sourcing ingredients, preparing dishes consistently, serving customers efficiently, and adjusting recipes based on feedback. LLM Ops provides the same kind of infrastructure. It’s the complete system to build, deploy, monitor, and improve language models at scale. Without it, you’re just cooking in your home kitchen, hoping for the best.
What is LLM Ops?
It’s the operational backbone for production-grade AI agents and applications powered by LLMs. It’s a specialized discipline that extends the principles of MLOps (Machine Learning Operations) to handle the unique lifecycle of large language models.
The core idea is to automate and streamline the entire process:
- Development: Managing prompts, fine-tuning models, and experimenting with different architectures.
- Deployment: Pushing models to production reliably and efficiently.
- Monitoring: Watching for performance issues, cost overruns, and unexpected behavior like hallucinations.
- Maintenance: Continuously improving the model based on real-world feedback and data.
LLM Ops ensures that your LLM-powered applications are reliable, scalable, and cost-effective.
How does LLM Ops differ from traditional MLOps?
While they share the same goals of automation and reliability, their focus is different. MLOps was built for a world of structured data and predictable outputs. LLM Ops is designed for the messy, unpredictable world of human language.
Here are the key distinctions:
- Input/Output Nature: Traditional MLOps deals with structured data like numbers and categories. LLM Ops is specifically tailored to handle unstructured text inputs (prompts) and generated text outputs (completions).
- Prompt Engineering: In MLOps, feature engineering is key. In LLM Ops, prompt engineering is a critical, first-class component. The prompt is like code; it needs to be versioned, tested, and optimized. This concept doesn’t really exist in the same way in traditional MLOps.
- Evaluation: MLOps uses clear metrics like accuracy or F1-score. Evaluating an LLM is much harder. LLM Ops requires new metrics to track things like toxicity, factuality, helpfulness, and the rate of hallucinations.
What are the key components of an LLM Ops pipeline?
A robust LLM Ops pipeline is a continuous loop, not a straight line. It typically includes these stages:
- Prompt Management: A system for creating, testing, versioning, and deploying prompts.
- Data Management: Preparing and versioning datasets for fine-tuning and evaluation.
- Model Fine-Tuning: The process of adapting a base LLM on specific data to improve its performance for a particular task.
- Continuous Evaluation: Automated testing against benchmark datasets and adversarial prompts to catch regressions, biases, and hallucinations before they hit production.
- Deployment & Inference: Serving the model through a scalable API, often with optimizations to reduce latency and cost.
- Monitoring & Observability: Tracking model performance, cost, latency, and output quality in real-time. This includes looking for drift and unexpected user interactions.
- Feedback Loop: Capturing user feedback and production data to inform the next cycle of prompt updates or model fine-tuning.
Why is LLM Ops essential for enterprise AI deployment?
Because moving from a cool demo to a reliable enterprise product is a massive leap. Enterprises can’t afford to have their customer-facing AI go rogue. LLM Ops provides the guardrails.
- Reliability and Consistency: It ensures the model behaves predictably.
- Scalability: It provides the infrastructure to serve thousands or millions of users without crashing.
- Cost Management: LLMs are expensive to run. LLM Ops includes tools for optimizing inference and monitoring costs to prevent budget blowouts.
- Risk Reduction: It establishes processes to monitor for harmful outputs, data leakage, and security vulnerabilities like prompt injection.
Look at the major players:
- OpenAI: uses a massive LLM Ops framework to deploy ChatGPT, constantly monitoring for harmful content and using human feedback (RLHF) to continuously improve the model.
- Anthropic: builds its LLM Ops around systematic evaluation, testing Claude models against its “Constitutional AI” principles to ensure safety before release.
- Cohere: provides LLM Ops infrastructure to its enterprise clients, allowing them to securely fine-tune and deploy models on their own data.
What challenges does LLM Ops address?
LLMs introduce a new class of operational headaches. LLM Ops is the solution to these specific problems.
- Hallucinations: Models making up facts. LLM Ops implements continuous evaluation to detect and measure factuality.
- Non-Deterministic Behavior: The same prompt can produce different outputs. Monitoring systems are needed to track the quality of these variable outputs.
- High Costs: Inference is computationally expensive. LLM Ops uses optimization techniques to make it more affordable.
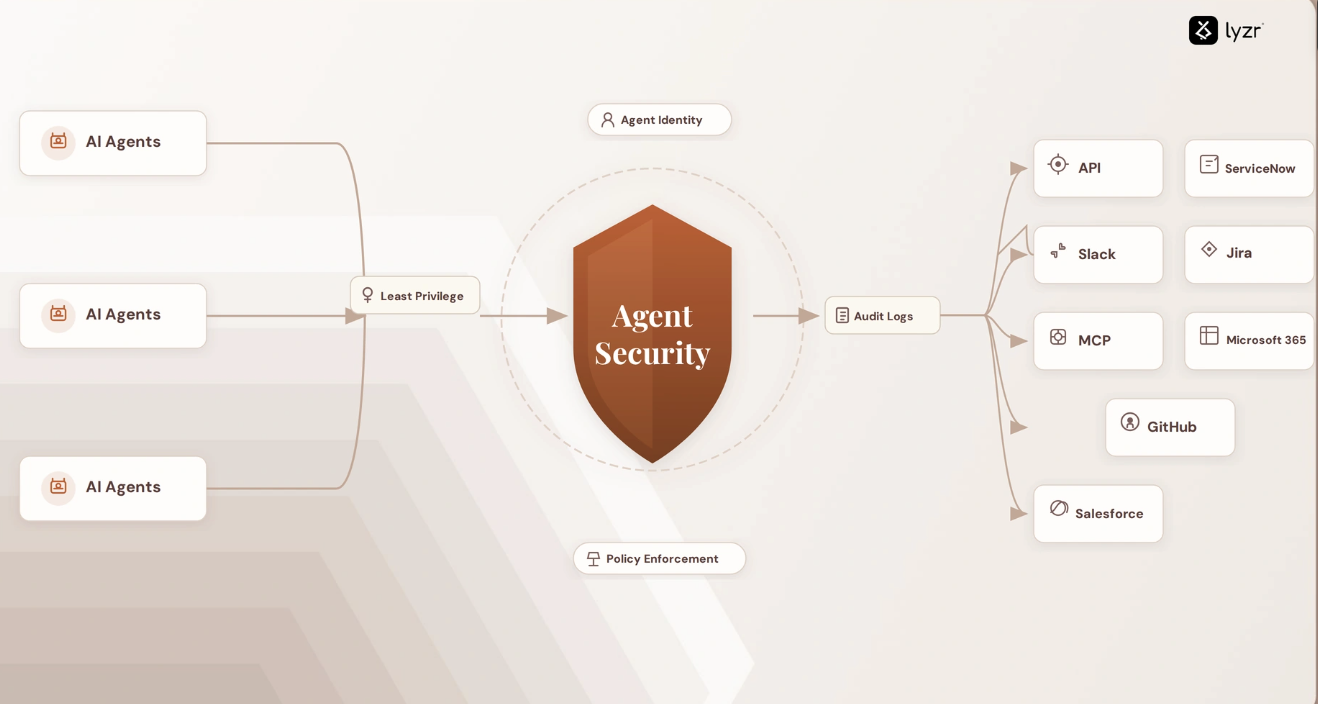
- Security Risks: New attack vectors like prompt injection require specialized security monitoring and input sanitization pipelines.
- Prompt Brittleness: A small change in a prompt can drastically alter the output. Prompt management systems help version and test prompts to ensure stability.
What technical mechanisms are used in LLM Ops?
The core isn’t about general coding; it’s about specialized frameworks and tools.
- Continuous Evaluation Frameworks: These are automated systems that run a battery of tests on an LLM before deployment. They check for performance degradation, test against known failure modes, and even use other LLMs to score the quality of the output.
- Prompt Management Systems: Think of these as Git for your prompts. They allow teams to version, test, and collaborate on prompts, treating them like a critical piece of the software stack.
- Inference Optimization Techniques: This is crucial for managing costs. Techniques include quantization (using smaller data types for model weights), batching (processing multiple requests at once), and caching (storing results for common queries).
Quick Test: Spot the LLM Ops Failure
Your company just launched a new AI customer service agent. After a week, you notice two things: your cloud computing bill has tripled, and customers are complaining the agent is giving rude answers.
Which parts of your LLM Ops pipeline have likely failed?
- Cost Management & Inference Optimization: The tripled bill points to unoptimized model serving.
- Monitoring & Evaluation: The rude answers mean your pre-deployment evaluation and real-time output monitoring failed to catch toxicity and negative sentiment.
Deep Dive: Your LLM Ops Questions Answered
How does prompt engineering fit into LLM Ops?
It’s a core discipline. In LLM Ops, prompts are treated as mission-critical assets. They are versioned, subjected to A/B testing, and managed within a CI/CD pipeline, just like application code.
What monitoring metrics are unique to LLM deployments?
Beyond standard metrics like latency and error rates, LLM Ops tracks output quality. This includes toxicity scores, sentiment analysis, PII (Personally Identifiable Information) detection, relevance to the prompt, and hallucination rates.
How do you handle version control for LLMs and their prompts?
You version them together. A specific version of an application should be tied to a specific model checkpoint and a specific version of the prompt template it uses. This ensures reproducibility and helps debug issues.
What are the best practices for LLM evaluation before deployment?
A multi-layered approach is best. This includes testing on standard academic benchmarks, using custom datasets that reflect your specific use case, and “red teaming,” where humans actively try to make the model fail or produce harmful content.
How can LLM Ops help reduce hallucinations and improve factuality?
Through a combination of techniques. Implementing Retrieval-Augmented Generation (RAG) provides the model with external facts. Continuous evaluation pipelines can check outputs against a knowledge base, and monitoring user feedback helps identify when and where the model is inventing things.
What infrastructure considerations are important for LLM Ops?
GPU availability and management are paramount. You also need scalable inference endpoints, low-latency vector databases (for RAG), and robust logging and monitoring infrastructure that can handle massive volumes of text data.
How does fine-tuning integrate with the LLM Ops lifecycle?
Fine-tuning is a planned, data-driven process. Monitoring might reveal that the model’s performance is drifting on a certain topic. This triggers a workflow to collect new data, fine-tune the base model, evaluate it, and deploy the new version.
What security practices are essential in LLM Ops?
Input sanitization to prevent prompt injection attacks is critical. Output filtering is also needed to ensure the model doesn’t leak sensitive data. Standard security practices like access control and network security are also essential.
How does LLM Ops support compliance and governance requirements?
By providing audit trails. LLM Ops systems log all prompts and completions, track model versions, and document evaluation results. This data lineage is crucial for demonstrating compliance with regulations and internal governance policies.
What tools and platforms are available for implementing LLM Ops?
The ecosystem is growing fast. It includes experiment trackers (MLflow, Weights & Biases), model hubs (Hugging Face), specialized observability platforms (Arize AI, TruEra), and development frameworks (LangChain, LlamaIndex) that provide components for building LLM Ops pipelines.
LLM Ops is the unglamorous but essential engineering discipline that turns the incredible potential of large language models into real, reliable, and safe products.