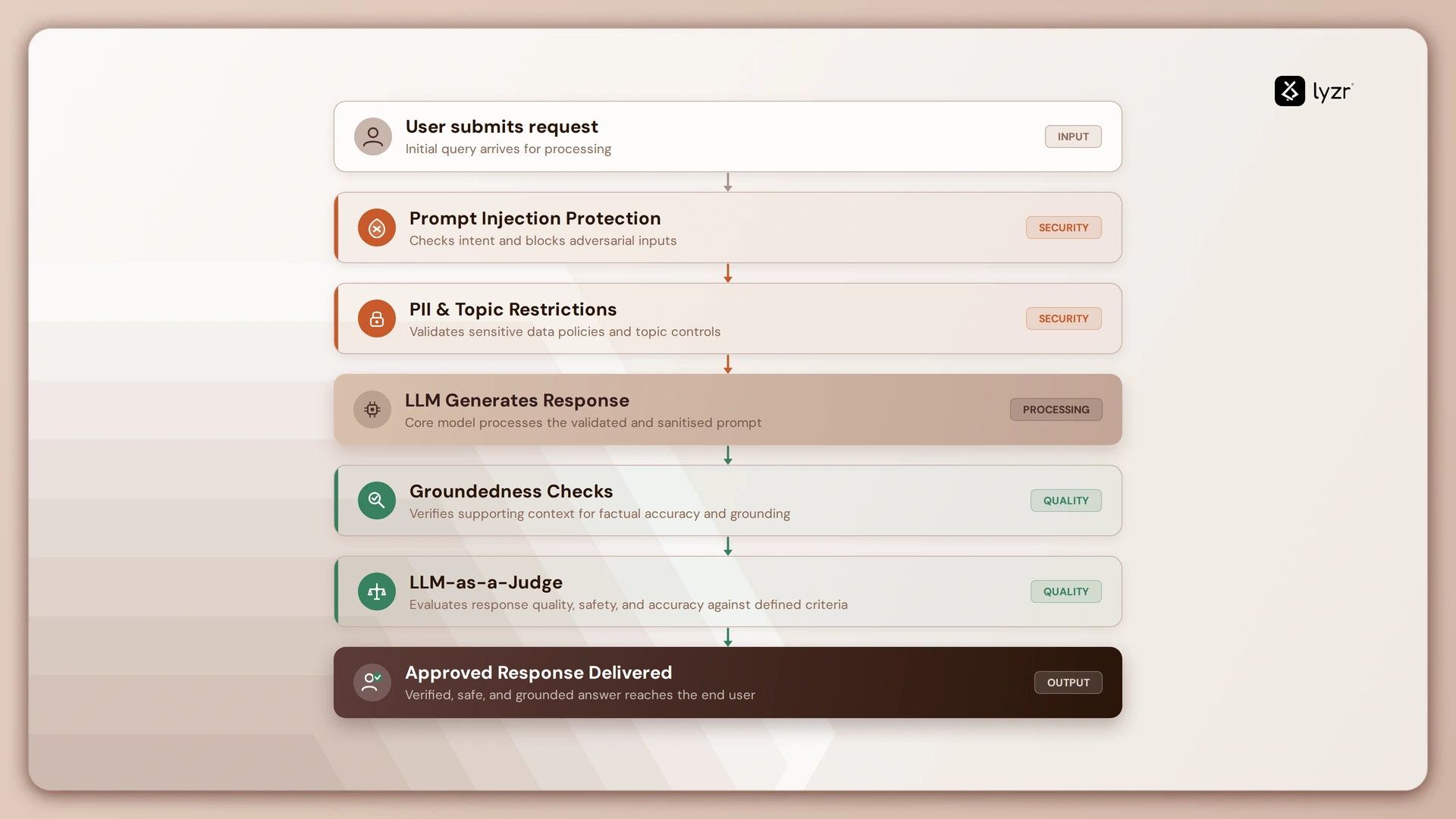
The most powerful AI models are often too big, too slow, and too expensive to be useful in the real world.
Model distillation is a process in AI where a small, efficient model is trained to mimic the behavior of a larger, more complex model to achieve similar performance with reduced computational resources.
Think of it like this.
You have a gourmet recipe from a five-star chef.
It has 50 ingredients and takes 8 hours. The result is perfect.
Model distillation is the process of creating a simplified weeknight version of that recipe.
It uses 10 ingredients, takes 30 minutes, and tastes 95% as good.
You get most of the flavor without the immense effort.
This process is what allows the power of massive AI to be packed into your smartphone or car, making advanced AI accessible, fast, and affordable.
What is model distillation in AI?
It’s a knowledge transfer technique.
Imagine you have two models:
- The Teacher Model: This is a large, complex, and highly accurate model. It’s powerful but slow and resource-intensive. Think of it as the research professor with deep knowledge.
- The Student Model: This is a smaller, simpler, and more efficient model. It’s lightweight but starts as a blank slate. Think of it as the eager student.
During distillation, the student model doesn’t just learn from the raw data.
It learns from the outputs of the teacher model.
The teacher provides nuanced guidance, teaching the student not just the correct answers, but the reasoning and probabilities behind them. This helps the smaller model learn the complex patterns captured by the larger one, but in a much more compact form.
Why is model distillation important?
Because size and speed matter.
Giant AI models that run in massive data centers are incredible for research, but they are impractical for many real-world applications.
Distillation is crucial for:
- Deployment on Edge Devices: Putting AI on smartphones, smart watches, cars, and IoT devices that have limited memory and processing power.
- Reducing Latency: Smaller models respond much faster, which is critical for real-time applications like voice assistants or autonomous driving.
- Lowering Costs: Running large models is expensive. Distilled models require significantly less computational power, reducing server costs and energy consumption.
- Improving Accessibility: It makes powerful AI capabilities available to a wider range of applications and users who don’t have access to supercomputers.
What techniques are used in model distillation?
The magic happens in the training process, using a few key mechanisms.
This isn’t just standard model training; it’s a guided mentorship.
- Teacher-Student Training: This is the core framework. The large, pre-trained “teacher” model processes the training data, and its outputs are used to train the smaller “student” model. The student’s goal is to replicate the teacher’s output as closely as possible.
- Soft Targets: This is the secret sauce. Instead of training the student on “hard” labels (e.g., this image is 100% a “cat”), you train it on the teacher’s “soft” targets. The teacher might say, “I’m 95% sure this is a cat, but there’s a 4% chance it’s a small dog and a 1% chance it’s a fox.” This extra information about uncertainty and relationships between classes is incredibly rich and helps the student learn nuances it would otherwise miss.
- Loss Function Adaptation: The process uses a special loss function. It’s a mathematical formula that measures how well the student is doing. It’s customized to simultaneously compare the student’s output to both the ground truth (the correct answer) and the teacher’s soft targets.
How is model distillation applied in real-world scenarios?
You’re likely using distilled models every day without realizing it.
- Google: When you use Google Assistant on your phone, many of the language processing tasks run directly on your device for speed. This is made possible by distilling massive language models down to a size that can run efficiently on mobile hardware.
- Tesla: A self-driving car needs to make split-second decisions. It can’t wait to send data to the cloud and get a response. Tesla uses distillation to compress powerful computer vision models so they can run in real-time on the car’s internal computers, analyzing road conditions and making driving decisions instantly.
- OpenAI: To make their powerful generative models more accessible and affordable for specific applications, OpenAI creates more efficient versions. This allows smaller companies to leverage the power of models like GPT without needing massive infrastructure.
What are the benefits of using model distillation for edge devices?
This is where distillation truly shines. “The edge” refers to local devices like your phone, not the cloud.
- Speed: Local processing eliminates network lag. The AI responds instantly because it doesn’t need to communicate with a distant server.
- Privacy: Sensitive data can be processed on the device itself instead of being sent to the cloud, which is a huge win for user privacy.
- Offline Functionality: Distilled models can run without an internet connection, making them reliable in areas with poor connectivity.
- Energy Efficiency: Smaller models consume far less battery power, which is critical for mobile and battery-operated devices.
Quick Check: Where would you use a distilled model?
Imagine you’re building three AI features. Which one absolutely requires a distilled model?
- An AI that analyzes massive scientific datasets to predict climate change patterns over the next century.
- A smartphone app that translates a spoken sentence into another language in real-time during a conversation.
- An internal company tool that generates a detailed monthly financial report overnight.
The answer is #2. The real-time translation app needs the low latency and offline capability that only a small, efficient, distilled model running on the device can provide.
Digging Deeper: Your Questions Answered
How do teacher and student models interact in distillation?
The teacher model acts as a guide. It processes the input data and produces a set of probabilities (soft targets). The student model then tries to match these probabilities. The difference between their outputs is used to update the student model, slowly teaching it to think like the teacher.
What are the trade-offs of model distillation?
The primary trade-off is performance for efficiency. While the goal is to retain as much accuracy as possible, the distilled student model will almost always have a slightly lower performance on benchmark tests than the massive teacher model it learned from.
Can distillation affect model accuracy?
Yes, typically there is a small drop in accuracy. The engineering challenge is to minimize this drop while maximizing the gains in speed and size reduction. A well-executed distillation can create a model that is 10x smaller and faster while only losing 1-2% accuracy.
What role does model distillation play in reducing the carbon footprint of AI applications?
A significant one. Large models require vast amounts of energy to run. By enabling the use of smaller, more efficient models for everyday tasks, distillation dramatically reduces the overall power consumption and associated carbon footprint of deployed AI systems.
Does model distillation support incremental learning?
Yes. You can use distillation to transfer knowledge from an updated teacher model to an existing student model, allowing the student to learn new information without needing to be completely retrained from scratch on the entire dataset.
Model distillation is a practical and essential technique for bridging the gap between cutting-edge AI research and real-world application.
It’s how we take the brilliant, massive minds of AI and give them the lean, agile bodies they need to work everywhere, for everyone.
Have you encountered an app that felt surprisingly fast and smart? It might have been a distilled model at work. Let me know your thoughts.