A Large Language Model (LLM) is an AI system trained on vast amounts of text so it can understand language, interpret questions, generate responses, summarise information, and assist with reasoning tasks.
Think of it as a highly trained text prediction engine.
It learns patterns from billions of sentences and uses that knowledge to generate human-like output.
Related: See also LLM Tokens and How LLMs Work.
How LLMs work behind the scenes
LLMs operate through three fundamental processes:
- Training – The model reads and learns patterns from a massive dataset of text.
- Encoding – Inputs are converted into numerical tokens the model can process.
- Prediction – The model generates one token at a time based on probability.
Modern LLMs use the transformer architecture, which relies on self-attention to understand relationships between different words in a sentence.
LLM inference explained
Inference is the stage where the LLM generates output from a user prompt.
It is separate from training.
During inference:
- Your input is broken into tokens
- The model processes these tokens using learned parameters
- It predicts and outputs one token at a time
- The process repeats until a complete answer is formed
Inference speed depends on the model size, GPU performance, quantization, and system optimization
LLM context window explained
The context window is the maximum amount of text an LLM can read, remember, and work with at one time.
A model with a larger context window can handle:
- Long documents
- Extended conversations
- Large code files
- Research papers and transcripts
Smaller windows may cause the model to “forget” earlier parts of the conversation.
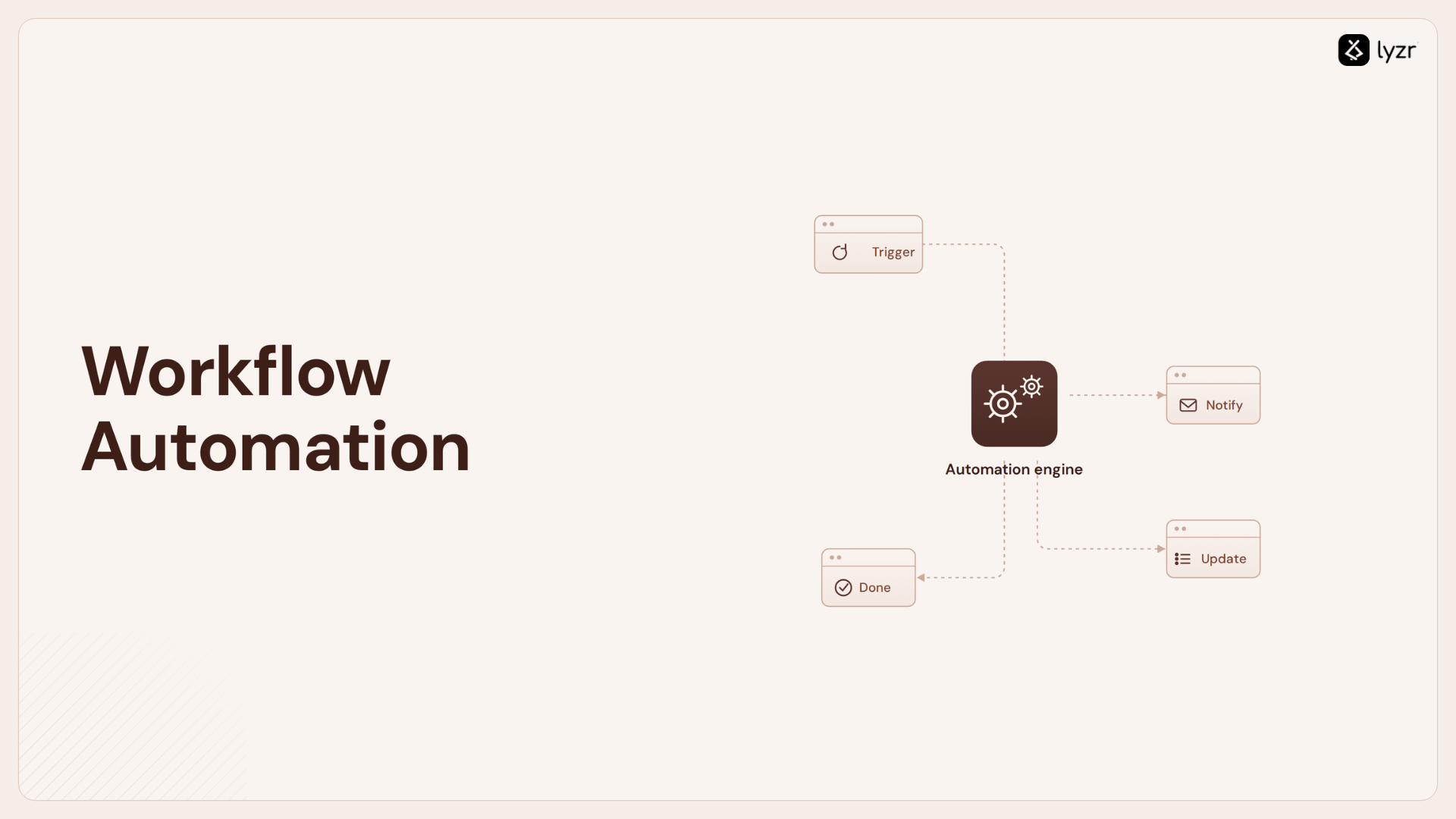
What is an LLM pipeline?
An LLM pipeline is the workflow used to process user input and generate responses.
A typical pipeline includes:
- Input parsing
- Tokenization
- Embedding generation
- Model inference
- Output formatting
- Delivery of the final answer
Enterprise pipelines may include guardrails, RAG, moderation filters, or validation agents to ensure safe and accurate results
LLM token explained
A token is the smallest unit of text an LLM processes.
It can be a whole word, part of a word, or punctuation.
Examples:
- “AI” → 1 token
- “learning” → may split into “learn” + “ing”
- A paragraph → could be 50–200 tokens
Token usage determines:
- Cost
- Context usage
- Model speed
- Response length
Related : Context Window.
Embedding vs LLM
Embeddings are numerical vector representations of meaning.
LLMs are generative models that produce text.
Embeddings are used for:
- Search
- Clustering
- Similarity scoring
- Document retrieval
LLMs are used for:
- Conversation
- Summaries
- Text generation
- Reasoning
- Multi-step agentic actions
Together, they power modern RAG systems.
RAG vs LLM
LLM Alone:
- Relies purely on pre-trained knowledge
- Cannot access new or private data
- More prone to hallucinations
RAG (Retrieval-Augmented Generation):
- Fetches information from databases, documents, and APIs
- Provides real-time, grounded facts
- Reduces hallucinations significantly
- Enhances accuracy for enterprise use cases
RAG is ideal for knowledge-heavy applications like HR, finance, healthcare, legal, and customer support.
Related: Why LLMs Hallucinate.
Why LLMs hallucinate
LLMs hallucinate because they are probabilistic models, not factual databases.
They generate text based on patterns — even if the correct information is missing.
Common causes:
- No grounding (no RAG)
- Insufficient domain knowledge
- Ambiguous or poorly framed prompts
- Biases in training data
- Overfitting patterns
- Missing context due to token limits
Reducing hallucinations typically requires RAG, validation layers, or fine-tuning.
Future Trends in LLMs
The evolution of LLMs points toward advancements in:
 1")
- Neural Architecture:
- Development of efficient and compact transformer models.
- Ethical AI:
- Addressing bias and ensuring fairness in language generation.
- Domain-Specific Applications:
- Enhanced performance through domain-targeted fine-tuning.
- Real-Time Language Understanding:
- Improved contextual grasp for dynamic, interactive environments.
FAQs
What can an LLM do?
LLMs can analyse text, summarise content, answer questions, generate responses, support agents, and perform reasoning tasks.
Why is an LLM called “large”?
Because it contains millions or billions of parameters learned during training.
Are embeddings faster than LLMs?
Yes — embeddings are lightweight mathematical vectors and do not generate text.
What happens if the context window is exceeded?
The model may drop or forget earlier parts of the input.
Does RAG eliminate hallucinations?
Not entirely, but it significantly reduces them by grounding answers in factual data.
Why do LLMs sound confident even when wrong?
Because they optimize for fluency and coherence, not certainty or factual accuracy.