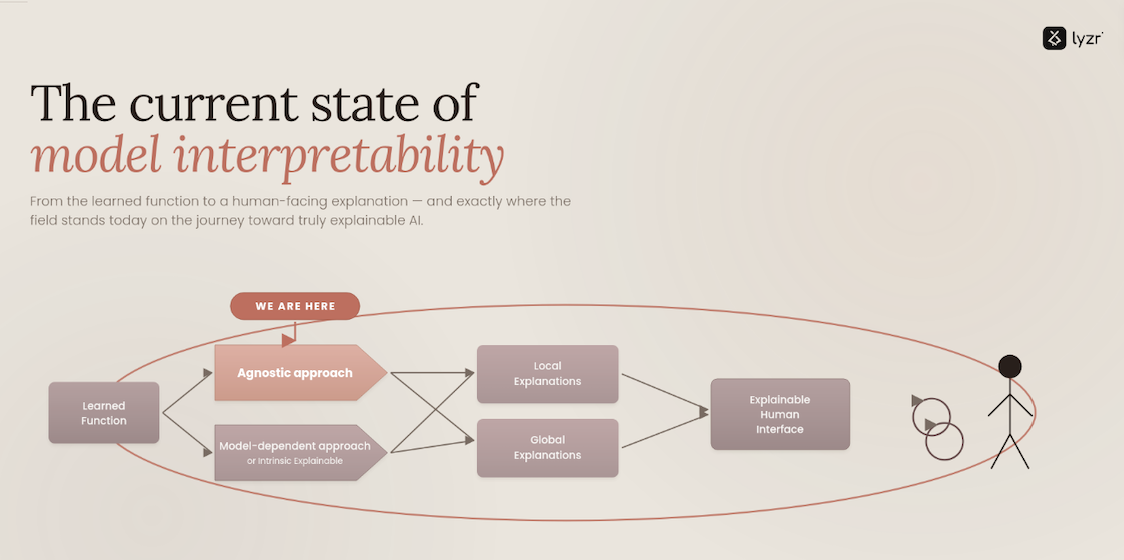
What is F1 Score?
The F1 Score is a metric that measures model performance by balancing precision and recall, providing a single score that reflects both false positives and false negatives.
How does the F1 Score Operate in Model Evaluation?
The F1 Score is a crucial metric in evaluating the performance of classification models, particularly when dealing with imbalanced datasets. It serves as a balance between precision and recall, providing a single score that encapsulates the model’s accuracy in identifying positive instances. Here’s how it operates:
- Precision: The ratio of true positive predictions to the total predicted positives, indicating the accuracy of positive predictions.
- Recall: The ratio of true positive predictions to the actual positives, reflecting the model’s ability to capture all relevant instances.
- F1 Score Calculation: The F1 Score is calculated using the formula: F1 = 2 * (Precision * Recall) / (Precision + Recall). This harmonic mean emphasizes the balance between the two metrics.
- Benefits: Using the F1 Score is particularly beneficial in scenarios where false positives and false negatives carry different costs. It helps in making informed decisions when the class distribution is uneven.
- Insights: Evaluating the F1 Score gives insights into the model’s robustness and its effectiveness in real-world applications, guiding further improvements in model training.
Overall, the F1 Score is an essential tool for data scientists and machine learning engineers to ensure their models perform optimally across various classification tasks.
Common Uses and Applications of F1 Score in Real-world Scenarios
The F1 Score is a crucial metric in the evaluation of machine learning models, especially in classification tasks. It provides a balance between precision and recall, helping data scientists and machine learning engineers understand model performance better. Here are some key applications of the F1 Score:
- Medical Diagnosis: In healthcare, F1 Score is used to assess models that predict diseases, balancing the trade-off between false positives and false negatives.
- Spam Detection: Email filtering systems utilize F1 Score to improve the accuracy of spam classification, ensuring relevant emails are not misclassified.
- Sentiment Analysis: In natural language processing, F1 Score helps evaluate the performance of sentiment analysis models by measuring their precision and recall in classifying sentiments.
- Fraud Detection: Financial institutions apply F1 Score in fraud detection systems to balance the risk of false alarms against missed fraudulent activities.
- Recommendation Systems: F1 Score is useful in assessing the quality of recommendations by measuring how well the system identifies relevant items for users.

What are the Advantages of Using F1 Score?
The F1 Score is a vital metric for evaluating model performance, particularly in classification tasks. It provides a balance between precision and recall, making it especially useful in scenarios where class distributions are imbalanced. Here are some key benefits of using the F1 Score:
- Balanced Evaluation: The F1 Score considers both false positives and false negatives, offering a more holistic view of model performance.
- Useful for Imbalanced Classes: In cases where one class is more prevalent than another, the F1 Score helps in assessing the model’s effectiveness across all classes.
- Enhances Decision Making: With a clear understanding of precision and recall, data scientists can make informed decisions on model adjustments.
- Improved Recall for Critical Applications: It ensures that important positive cases are not missed, crucial in fields like healthcare and finance.
- Standardized Metric: Widely recognized in the industry, making it easier to compare different models and approaches.
Incorporating the F1 Score into model evaluation can significantly enhance the understanding of a model’s predictive capabilities.
Are there any Drawbacks or Limitations Associated with F1 Score?
While the F1 Score provides a balanced measure of a model’s performance by considering both precision and recall, it does have some limitations. One drawback is that it may not give a complete picture of model performance, especially in cases of imbalanced datasets where one class is more prevalent than the other. Additionally, the F1 Score does not account for true negatives, which can be significant in specific contexts. These challenges can lead to misinterpretations of a model’s effectiveness in certain applications.
Can You Provide Real-life Examples of F1 Score in Action?
For example, in the healthcare industry, F1 Score is used by organizations to evaluate predictive models for disease diagnosis. By focusing on both precision (correct diagnoses) and recall (identifying all patients with the disease), healthcare providers can ensure that they minimize false negatives, which is crucial for patient safety. This demonstrates the importance of F1 Score in making informed decisions that affect patient outcomes.
How does F1 Score Compare to Similar Concepts or Technologies?
Compared to accuracy, which only measures the overall correctness of a model’s predictions, the F1 Score differs in its approach by focusing on the balance between precision and recall. While accuracy can be misleading in imbalanced datasets, F1 Score provides a more nuanced evaluation. This makes F1 Score more effective for classification tasks where the costs of false positives and false negatives differ significantly.
What are the Expected Future Trends for F1 Score?
In the future, the F1 Score is expected to evolve with advancements in machine learning and data science methodologies. As models become more complex and datasets continue to grow, there will likely be a greater emphasis on multi-class F1 scoring and its adaptation for real-time applications. These changes could lead to more robust evaluation metrics that provide deeper insights into model performance across various scenarios.

What are the Best Practices for Using F1 Score Effectively?
To use F1 Score effectively, it is recommended to:
- Ensure proper data preprocessing to avoid biases.
- Use F1 Score in conjunction with other metrics like precision, recall, and accuracy for a comprehensive evaluation.
- Consider the specific context of the problem to determine the importance of precision vs. recall.
- Monitor changes in F1 Score during model training to track performance improvements.
Following these guidelines ensures a well-rounded assessment of model performance.
Are there Detailed Case Studies Demonstrating the Successful Implementation of F1 Score?
One notable case study is from a leading e-commerce company that implemented machine learning models to predict customer churn. By utilizing the F1 Score to evaluate their models, they achieved a notable increase in correctly identifying at-risk customers. This led to a targeted marketing campaign that improved customer retention rates by 15%. The use of F1 Score was crucial in balancing the trade-offs between false positives and false negatives, resulting in more effective strategies.
What Related Terms are Important to Understand along with F1 Score?
Related Terms: Related terms include Precision and Recall, which are crucial for understanding F1 Score because they form the basis of its calculation. Precision measures the accuracy of positive predictions, while Recall assesses the model’s ability to identify all relevant instances. Understanding these terms helps in grasping how F1 Score integrates these metrics to provide a balanced evaluation of model performance.
What are the Step-by-step Instructions for Implementing F1 Score?
To implement F1 Score, follow these steps:
- Define the classification problem and gather the dataset.
- Split the data into training and testing sets.
- Train your model using the training data.
- Make predictions on the testing data.
- Calculate precision and recall based on the model’s predictions.
- Compute the F1 Score using the formula: 2 * (Precision * Recall) / (Precision + Recall).
These steps ensure a thorough evaluation of your model’s performance.
Frequently Asked Questions
- Q: What is the F1 Score?
A: The F1 Score is a metric that combines precision and recall into a single score to help evaluate the performance of a classification model.
1: Precision measures the accuracy of positive predictions,
2: Recall measures the ability to identify all relevant instances. - Q: Why is the F1 Score important?
A: The F1 Score is important because it provides a better measure of a model’s performance when dealing with imbalanced datasets.
1: It considers both false positives and false negatives,
2: It helps in understanding the trade-off between precision and recall. - Q: How is the F1 Score calculated?
A: The F1 Score is calculated using the formula: F1 = 2 * (precision * recall) / (precision + recall).
1: This formula ensures that both precision and recall are considered,
2: It yields a score between 0 and 1, where 1 is the best possible score. - Q: When should I use the F1 Score?
A: The F1 Score should be used when you need a balance between precision and recall.
1: It is particularly useful in situations where false positives and false negatives carry different costs,
2: It is ideal for tasks like medical diagnosis or fraud detection. - Q: What are the benefits of using the F1 Score?
A: The benefits of using the F1 Score include providing a single metric for model evaluation and helping to focus on the quality of predictions.
1: It allows for easier comparison between models,
2: It is helpful in tuning model parameters. - Q: What insights can I gain from the F1 Score evaluation?
A: The F1 Score evaluation can provide insights into how well a model performs in identifying relevant instances.
1: A high F1 Score indicates a good balance between precision and recall,
2: A low F1 Score suggests potential issues with the model’s predictions. - Q: Can I use the F1 Score for all types of classification tasks?
A: While the F1 Score is useful for many classification tasks, it may not be suitable for all.
1: It is best for imbalanced classes,
2: For balanced datasets, accuracy might be a better metric.