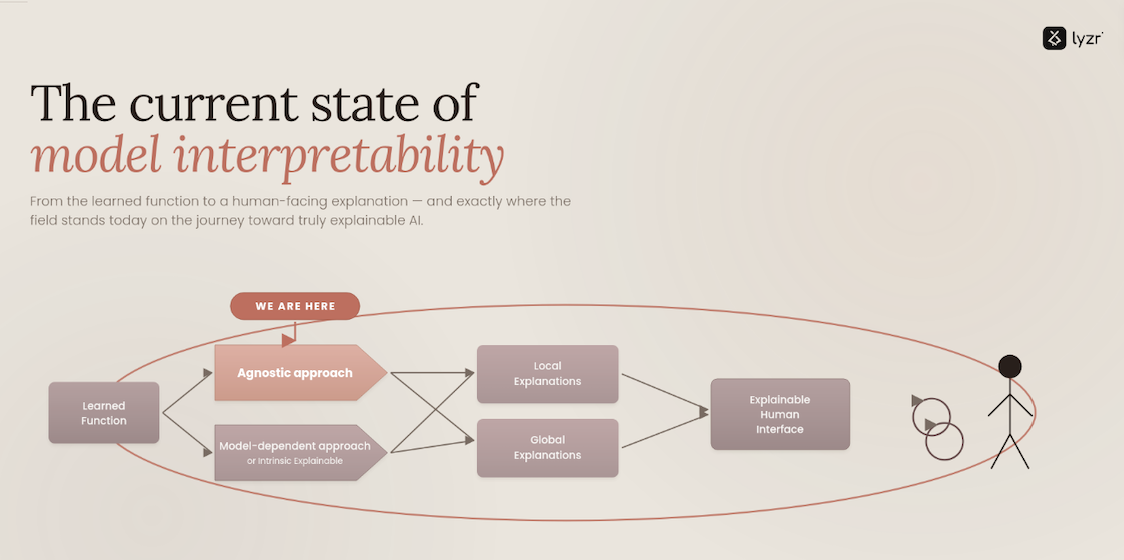
I have been working on ChatGPT since its launch in early 2023. And later, with GPT3.5 and GPT4 APIs, building AI applications. From my experience, having worked extensively on RAG (Retrieval Augmented Generation) and LLM Fine-tuning, 90% of LLM use cases are best solved with Prompt + RAG as the stack.
Prompt Engineering guides like https://www.promptingguide.ai/ often focus on the types of prompting techniques. I recently wrote a blog on introducing a new prompting technique for summarization.
While these are the best ways to understand how prompt engineering works, the parameter settings of prompts are often ignored. This blog provides a detailed explanation of what these parameters are and how to set them for the best prompt performance.
What are these parameters?
 | Model: Select between GPT3.5 Turbo, GPT4, and GPT4 Turbo models based on your needs. Temperature: Controls randomness. Lowering results in less random completions. As the temperature approaches zero, the model will become deterministic and repetitive. Maximum Length: The maximum number of tokens to generate shared between the prompt and completion. The exact limit varies by model. (one token is roughly four characters of standard English text) Stop Sequences: Up to 4 sequences where API will stop generating further tokens. The return text will not contain the stop sequence. Top P: Controls diversity via nucleus sampling. A Top P of 0.5 means half of all likelihood-weighted options are considered. Frequency Penalty: How much should the new tokens be penalized based on their existing frequency in the text so far? Decreases the model’s likelihood to repeat the same line verbatim. Presence Penalty: How much should new tokens be penalized based on whether they appear in the text so far? Increases the model’s likelihood of talking about new topics. |
The key is understanding and adjusting these parameters to suit specific needs, be it writing technical articles, planning activities, creating product stories, drafting product requirements, or developing architecture documents. As OpenAI’s interface for ChatGPT evolves, current settings don’t allow pre-setting the tone for an entire conversation, but adjusting parameters for each prompt can still yield impressive results.
Start here: https://platform.openai.com/playground?mode=chat

Crafting Engaging Travel Blogs
- Parameters:
- Temperature: 0.7
- Max Length: 600
- Top P: 0.9
- Frequency Penalty: 0.0
- Presence Penalty: 0.0
- Stop Sequence: “\n\n”

Explanation & Expansion: Travel blogs need to be informative yet captivating. A temperature of 0.7 allows for factual information and engaging storytelling. A 600-word limit is ideal for detailed travel experiences without overwhelming the reader. The high Top P value of 0.9 encourages creative and diverse descriptions of destinations. The absence of frequency and presence penalties allows for the natural repetition of key travel details, enhancing the narrative flow. The stop sequence helps in structuring the blog for better readability.
Creating Healthy Meal Plans
- Parameters:
- Temperature: 0.5
- Max Length: 200
- Top P: 1.0
- Frequency Penalty: 0.3
- Presence Penalty: 0.0
- Stop Sequence: “\n\n”
Explanation & Expansion: Accuracy and simplicity are crucial for meal plans. A lower temperature of 0.5 ensures reliable and straightforward dietary suggestions. A 200-word limit keeps the plans concise and easy to follow. A top P value of 1.0 allows for various nutritional options and combinations. The frequency penalty of 0.3 helps avoid repetitive food suggestions, while the absence of a presence penalty maintains a natural tone. The stop sequence aids in organizing the meal plan effectively.
Generating Engaging Mystery Stories
- Parameters:
- Temperature: 0.8
- Max Length: 500
- Top P: 0.7
- Frequency Penalty: 0.2
- Presence Penalty: 0.5
- Stop Sequence: “\n\n”
Explanation & Expansion: Mystery stories require an element of suspense and intrigue. A higher temperature of 0.8 fosters creativity for unexpected plot twists. A 500-word limit keeps the story engaging and concise. A top P value of 0.7 balances creative ideas and narrative coherence. The frequency and presence penalties of 0.2 and 0.5, respectively, prevent the overuse of clichés while maintaining a smooth flow. The stop sequence helps in structuring the story for maximum impact.
Drafting Effective Marketing Copy
- Parameters:
- Temperature: 0.7
- Max Length: 400
- Top P: 0.9
- Frequency Penalty: 0.5
- Presence Penalty: 0.2
- Stop Sequence: “\n\n”
Explanation & Expansion: Marketing copy needs to be clear, persuasive, and engaging. A temperature of 0.7 balances creativity with coherence. A 400-word limit ensures the copy is concise yet informative. A high top P value encourages diverse and appealing language. Frequency and presence penalties of 0.5 and 0.2, respectively, help avoid repetition and maintain a natural flow. The stop sequence aids in segmenting different aspects of the marketing message.
Developing Software Documentation
- Parameters:
- Temperature: 0.6
- Max Length: 800
- Top P: 0.8
- Frequency Penalty: 0.2
- Presence Penalty: 0.3
- Stop Sequence: “\n\n”
Explanation & Expansion: Software documentation requires clarity and technical accuracy. A temperature of 0.6 minimizes randomness while allowing for necessary detail. An 800-word limit provides sufficient space for comprehensive explanations. A top P value of 0.8 ensures the documentation is coherent and logically structured. Frequency and presence penalties of 0.2 and 0.3, respectively, balance technical terms with readability. The stop sequence helps in organizing the documentation effectively.
As I mentioned in the introduction, prompts are more powerful than most of us think. Intelligent usage of the right prompting techniques with the right parameters setting will tremendously improve the performance of GPT workloads.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here