Chatbot 1")
1. Defining the Use Case
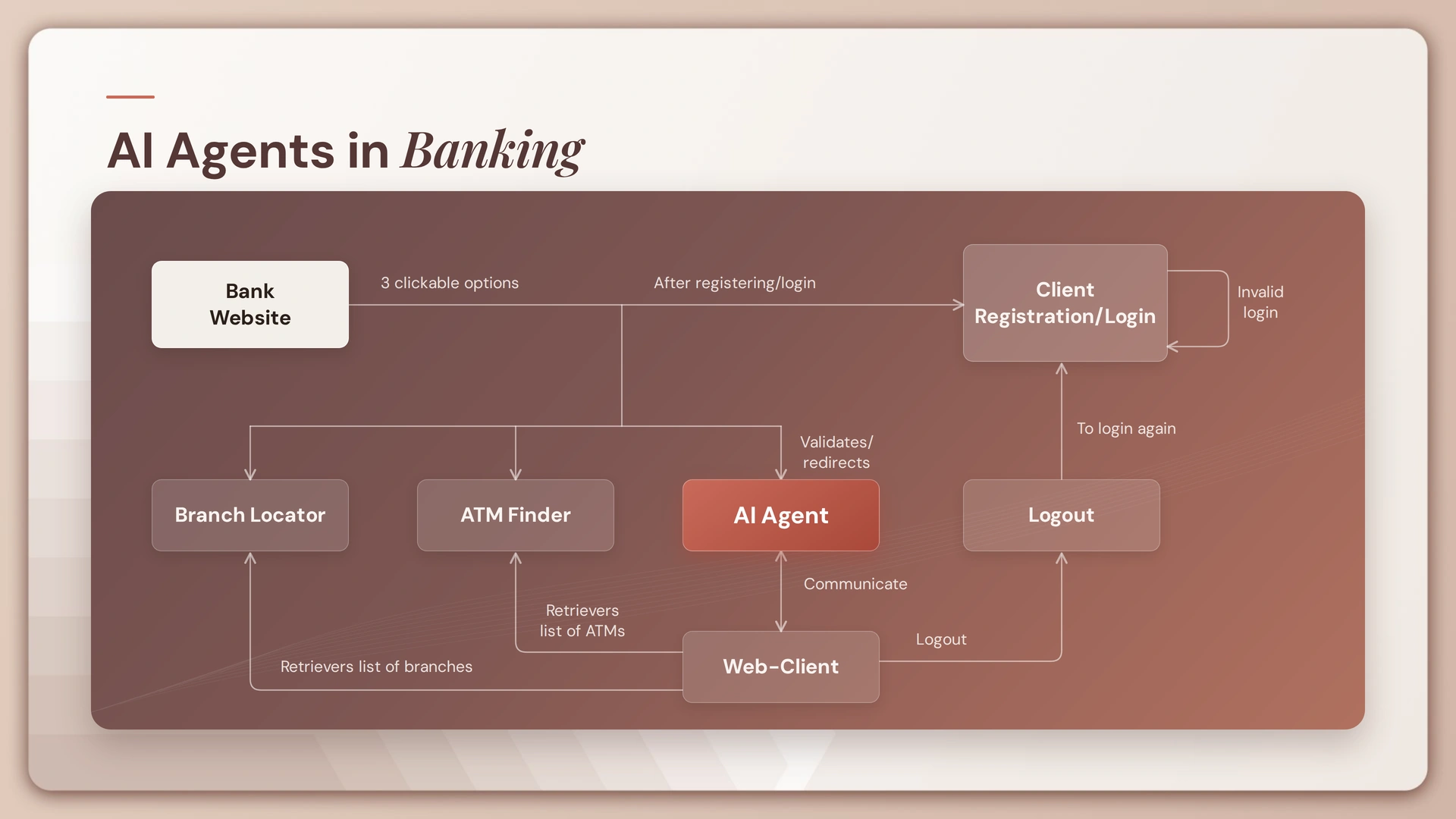
The journey to building a state-of-the-art chatbot with Generative AI and Large Language Models (LLMs) begins with a crucial step: defining the use case. It’s essential to ask, “Why do we need a chatbot?” This could be for customer support, sales assistance, or enhancing user engagement. Often, the mistake lies in misidentifying the problem. It might only sometimes be a chatbot that’s needed; sometimes, what’s required could be a sophisticated question-answering system or autonomous agents. Accurately defining the use case is pivotal in determining whether a chatbot is the right solution.
2. Identifying Data Sources
Once the need for a chatbot is established, the next vital step is identifying appropriate data sources. These sources could be diverse, ranging from PDFs, text files, and images, to videos, and data from structured or NoSQL databases. They could also include HTML pages and JSON files. Understanding the nature of these sources is crucial in designing an effective chatbot architecture, as it influences how the chatbot will process and respond to information.
Gobble.bot is a good example. The maker converts all source data into one simple text file. This make it easier for training or embedding. Gobble Bot converts youtube videos with transciptions, public websites and files with extensions: .TXT, .MD, .XSL, .PDF, .DOC, .DOCX, .ODT, .OTT, .RTF, .HTML, .HTM, .ATOM, .RSS, .XML, .XLS, .XLSX, .XLSB, .XLSM, .XLTX, .CSV, .ODS, .OTS, .PPTX, .POTX, .ODP, .OTP, .ODG, .OTG into one simple .txt file.
3. Data Normalization
A key lesson learned through the experience of building several enterprise-class chatbots is the importance of data normalization. This involves converting various data formats into a unified format that can be efficiently vectorized by embedding models and processed by LLMs. For instance, PDFs and videos should be translated into text files, with special attention to converting tables and images within PDFs into equivalent text. This step significantly reduces the load on embedding models and enhances the performance of retrieval engines. Data normalization, therefore, plays a critical role in the efficiency and effectiveness of a generative AI chatbot.
4. Chunking and Overlap
Once the data is normalized, the next crucial step in chatbot development is the process of chunking and establishing an overlap between chunks. Chunking involves dividing extensive text documents into smaller, manageable segments. These chunks are then fed into an embedding model to be vectorized and stored. The challenge lies in maintaining continuity between chunks. A common practice is to create chunks of about a 1000 words, with a 20-word overlap. This overlap ensures that the end of one chunk smoothly transitions into the beginning of the next, maintaining context continuity. However, it’s beneficial to experiment with different chunk sizes and overlaps to identify the most efficient structure for your specific use case.
5. Evaluating Chunk Sizes
Experimentation is key in determining the optimal chunk size. For instance, I conducted an experiment to discover the chunk size that best suited my needs. Click here to check the experiment.
Llama Index team has provided a detailed blog post on evaluating various chunk sizes for RAG performance.
Lyzr’s Enterprise SDKs for Chatbots, which have RAG as the underlying framework, allow you to dynamically assign the chunk sizes and overlap sizes to test the output for various chunk sizes.
6. Selection of Embedding Models
Choosing the right embedding model is another critical decision. There is no one-size-fits-all solution; various models offer different advantages. The MTEB English leaderboard by Hugging Face is an excellent resource for comparing models.
https://huggingface.co/spaces/mteb/leaderboard
In our experience, models like Voyage, BGE, and OpenAI’s text-ada have shown promising results for chatbot applications. The key is to experiment with different models to find the one that aligns best with your data type and sources.
Lyzr’s Enterprise SDKs also allow users to choose the embedding model of their choice. 20+ embedding models are supported out-of-the-box including the likes of Voyage, OpenAI Text-ada, Jina, BGE and more.
7. Fine-Tuning Embedding Models
Another aspect to consider is fine-tuning the embedding models. One experiment by Llama Index suggests that fine-tuning can enhance performance. This process involves adapting a base embedding model to better suit your specific data, potentially improving its efficiency.
However, this might not always be necessary; in some cases, as long as other parameters are well-managed, the difference in results may be minimal. Nevertheless, fine-tuning remains an option worth exploring.
8. Metadata Integration
A pivotal aspect of vector database management is the incorporation of metadata. Storing vector embeddings with associated metadata significantly speeds up the retrieval process and is highly beneficial for post-processing search results. Metadata filtering becomes integral to ensuring that the retrieval system can quickly and accurately access the relevant vectors.
9. Multi-Indexing Approach
The concept of multi-indexing is crucial, especially when metadata alone is insufficient for data retrieval. In a multi-index setup, different types of data, such as sales, marketing, and procurement, are stored in separate indices. This approach, combined with metadata, substantially enhances the retrieval capabilities of the generative AI engine by facilitating faster and more accurate data extraction.
10. Utilizing Collections within Indices
Beyond multi-indexing, the strategy of using collections within each index further refines the search process. For example, within the sales index, data can be categorized into product sales, service sales, and recurring sales and store them as vector collections. This subdivision allows for even more precise searches, greatly improving the effectiveness of the chatbot’s retrieval-augmented generation engine.
With Lyzr’s Enterprise SDKs, users can now create multiple collections and retrieve search results based on the collection just by passing the right paramters.
11. Selection of Indexing Algorithms
The choice of indexing algorithms plays a significant role in the performance of vector databases. While the K-Nearest Neighbors (KNN) algorithm is commonly used in data science, vector databases often utilize the Approximate Nearest Neighbor (ANN) algorithm. Libraries like Facebook’s Faiss exemplify the use of ANN.
While vector compression can lead to some precision loss, advanced database engines like Weaviate effectively manage this issue, reducing the need for manual adjustments. Therefore, selecting the right vector database is crucial as it can alleviate much of the workload related to indexing.
12. Choosing the Right Vector Database
The selection of an appropriate vector database is a critical decision in crafting a state-of-the-art chatbot. There are various options available, each with its unique features. For instance, PGvector by Supabase integrates vector database capabilities into a PostgreSQL model, while MongoDB Atlas incorporates vector functionalities into a NoSQL DB framework.
Alternatively, specialized vector databases like Weavaite are specifically designed for these applications. Weaviate, for example, handles indexing algorithms, metadata management, and multi-indexing efficiently, simplifying the overall process. Our project, www.theYCbot.com runs on Weaviate without any parameter finetuning discussed in this blog, and exemplifies the effectiveness of choosing an advanced database system.
All of Lyzr’s Open-Source SDKs run on Weaviate and Lyzr’s Enterprise SDKs also has Weaviate Vector Database as the default choice. Ofcourse, customers can choose any other vector database of their choice from the wide range offered by Lyzr Enterprise SDKs – Pinecone, PGvector, Qdrant, Chroma, Atlas, Lance, etc.
13. Query Rephrasing
Implementing query transformations is a burgeoning technique that enhances chatbot performance. This involves using Large Language Models (LLMs) to rephrase user queries, allowing multiple attempts to refine the search and yield the most accurate results. While this might slightly slow down the chatbot, the trade-off is a significant improvement in the precision of responses, especially for knowledge-based or question-answering bots.
14. Hypothetical Document Embeddings (HyDE)
Another innovative query transformation approach is Hypothetical Document Embeddings (HyDE). Here, an LLM like GPT creates a hypothetical response to a query, and the chatbot then searches for vector embeddings that closely match this hypothetical response. This method leverages the power of semantic search, using both the query and the generated response to find the most relevant and accurate answer.
Lyzr Enterprise SDK’s allow you to choose the query transformation of your choice. The best way to arrive at the right Chatbot architecture is to try various permutations combinations that results in desired performance.
15. Retrieval Parameters: Semantic, Keyword, and Hybrid Searches
In the realm of chatbot development, the choice of retrieval parameters is a critical aspect. Deciding between semantic search, keyword search, or a hybrid approach is pivotal.
Furthermore, the selection between sparse and dense retrieval methods greatly influences the chatbot’s effectiveness. These choices form the foundation of how the chatbot will process and retrieve relevant information.
16. Advanced Retrieval Strategies
Diving deeper into retrieval strategies, various techniques can be employed to optimize the chatbot’s performance. Llama Index provides valuable insights into different Retrieval-Augmented Generation (RAG) techniques.
 Chatbot 2")
For instance, auto-merger retrieval combines multiple search results in a layered approach, while hybrid fusion search blends keyword and vector search results, re-ranking them for optimal relevance. However, it’s important to note that these advanced techniques may incur additional costs due to potential extra LLM calls.
This being a key paramter that infuences RAG performance greatly, Lyzr Enterprise SDKs allow you to choose among the many RAG techniques by just passing the desired RAG technique as a paramter.
17. Auto-Selection and Customization of RAG Techniques
The Lyzr Chatbot SDK stands out by automatically selecting the most appropriate RAG technique for a given chatbot. However, it also offers the flexibility to override this selection by specifying a desired RAG technique, allowing for tailored optimization based on the chatbot’s specific needs.
This is a standout feature of Lyzr’s Enterprise SDKs. This feature enables automated testing of various RAG techniques to arrive at the best-suited model. This feature is in the internal-beta testing phase.
18. Re-rankers for Enhanced Coherence
Re-rankers play a significant role in refining search results. The Coherent Re-ranker, for example, prioritizes search results that closely match the user’s query. An alternative approach involves using an LLM to re-rank the results, further enhancing the relevance of the final output. Lyzr SDKs allow manually choosing a re-ranker or rely on its advanced algorithm to select the most suitable re-ranking technique.
19. Leveraging LLMs for Interpretation and Output Generation
LLMs, such as GPT-4, are integral in interpreting search results and producing human-readable outputs. These models excel in summarizing and organizing information retrieved from vector databases, transforming it into coherent and relevant responses. Additionally, fine-tuning LLMs can further tailor the responses to align more closely with the desired brand or industry identity.
Lyzr Enterprise SDKs allow you to seamlessly connect and switch between various LLMs including GPT3.5, GPT4, GPT4Turbo, Claude, Llama2, Mistral-7B, Mixtral 8x7B and other 100+ open-source models available through HuggingFace APIs.
Shout out to LiteLLM open-source contribution in helping Lyzr SDKs seamlessly connect with multiple LLMs.
20. The Significance of Prompting in LLMs
Large Language Models (LLMs) heavily depend on the quality of prompts they receive. A basic one-shot prompt, like the one used in theycbot.com, can be effective, but exploring various prompting techniques can significantly enhance the chatbot’s performance. Greg Brockman, co-founder of OpenAI, emphasized the importance of prompting in leveraging the full potential of GPT4. Techniques such as FewShot, ChainOfThought, ReAct, and combinations like ChainOfThought plus FewShot or ReAct plus FewShot are among the popular methods. Resources like the prompt engineering guide offer extensive insights into these techniques.
 Chatbot 3")
Source: https://www.promptingguide.ai/
21. Customizable Prompting in Lyzr SDK
Lyzr SDKs offers flexibility in selecting and comparing different prompting techniques, allowing for a tailored approach in optimizing chatbot outputs. For those who prefer not to experiment within the chatbot application itself, due to the SDK’s complexity, Lyzr Enterprise Hub offers a more specialized environment. This platform, exclusive to enterprise SDK customers, enables testing and comparison of up to four different prompts simultaneously, facilitating a comprehensive evaluation of various prompting techniques and LLM models.
 Chatbot 4")
22. Choosing the Right LLM
Another critical decision is selecting the most suitable LLM for the chatbot. Options range from base LLMs like GPT4 to fine-tuned versions of the same or even open-source models such as Mixtral or Llama2. The choice hinges on factors like security, data privacy, and the desired quality of output. Lyzr Enterprise SDKs integrate with a broad spectrum of LLMs, including GPT3.5, GPT4, GPT4Turbo, Claude, Llama2, Mistral-7B, Mixtral 8x7B and other 100+ open-source models available through HuggingFace APIs.
Or you could also host your own open-source LLM with Brev.dev – a GPU as a service provider. Lyzr natively integrates with brev.dev.
23. Memory Handling Capabilities
One of the most crucial elements in advanced chatbot design is its memory-handling capability. A chatbot without a robust memory is essentially a basic question-answering engine. Recalling and utilizing previous interactions (memory points) significantly enhances a chatbot’s contextual awareness, directly impacting the user experience. At Lyzr, we have achieved a milestone of integrating up to 50 memory points, far exceeding the standard capacity. This extended memory allows for a more nuanced and contextually aware interaction, offering a superior user experience.
24. The Role of Summarization in Memory Handling
Summarization is intrinsically linked to memory handling in chatbots. It’s vital for the chatbot to summarize past interactions to maintain context continuity accurately. Ineffective summarization can lead to loss of context or the creation of an entirely new, unintended context, resulting in a suboptimal user experience. Lyzr employs the SSR (Split Summarize Rerank) prompting technique for high-quality summarization, although it is a resource-intensive method. While not always recommended for typical chatbot applications due to its complexity, SSR prompting is exceptionally effective for a knowledge base or advanced question-answering systems. For standard chatbot scenarios, other forms of light-weight summarization techniques are integrated within the Lyzr SDK.
Try the effectiveness of SSR prompting with Lyzr’s demo – https://youtube10.streamlit.app/
25. Testing and Optimization for Chatbot Deployment
The effectiveness of various chatbot elements—ranging from memory handling and summarization techniques to other parameters—can only be truly assessed through comprehensive testing. This process is crucial for determining the most effective combination of features that deliver accuracy and an optimal user experience.
Lyzr’s extensive network of implementation partners plays a pivotal role in this phase. They offer end-to-end support, from use case definition and data source identification to normalization and parameter testing, ensuring the chatbot is fine-tuned for production deployment. And Lyzr SDKs serve as a powerful tool throughout this process, streamlining and simplifying the development of State-Of-The-Art (SOTA) chatbots.
26. RLHF: Reinforcement Learning with Human Feedback
Beyond constructing a functional chatbot, it’s essential to equip it with mechanisms for continuous self-improvement. This is where Reinforcement Learning (RL) becomes crucial. In our approach, we’ve integrated two types of RL: Reinforcement Learning with Human Feedback (RLHF) and Reinforcement Learning with AI Feedback (RLAIF). These methods ensure that the chatbot evolves not only from new data inputs but also from its interactive experiences.
RLHF revolves around enhancing the chatbot based on user feedback. The feedback can be integrated into the chatbot’s learning process, effectively ‘rewarding’ it for improved performance. This can be implemented in several ways. A simple thumbs-up/thumbs-down mechanism offers binary feedback, while presenting users with a selection of responses for them to choose the most appropriate one provides more nuanced feedback. This latter method is particularly useful during the initial testing and acceptance phases. As the chatbot’s accuracy improves, the feedback mechanism can be streamlined to the simpler binary model. This approach mirrors the strategies employed by organizations like OpenAI in the development stages of advanced chatbots like ChatGPT.
27. RLAIF: Reinforcement Learning with AI Feedback
While human feedback is invaluable, it can be a slower process compared to AI-generated feedback. RLAIF involves creating AI agents that simulate human interactions, offering rapid feedback to the chatbot. This method is especially relevant when the chatbot interacts with downstream agents or other software systems. Error codes or inefficiencies detected in these interactions can be fed back into the chatbot as AI feedback, thereby enhancing its retrieval accuracy and response quality.
Conclusion: Synthesizing State-of-the-Art Chatbot Architecture
Reflecting on the Chatbot Development Journey
This article has traversed the multifaceted landscape of building a state-of-the-art chatbot architecture, exploring a plethora of parameters, techniques, and considerations. The journey of chatbot development is intricate, requiring careful attention to numerous aspects ranging from data source selection and prompt engineering to the choice of embedding models and LLMs.
The Role of Lyzr SDK in Streamlining Chatbot Development
Despite the inherent complexity of chatbot architecture, the Lyzr team has made significant strides in distilling these multifarious elements into an accessible and powerful SDK. This achievement represents a remarkable feat in the realm of AI and chatbot technology, enabling developers to approach the creation of sophisticated chatbots with greater ease and efficiency. The Lyzr SDK encapsulates the essence of state-of-the-art chatbot development, simplifying it into a manageable process while retaining a high degree of capability and versatility.
The Continuum of Choices and the SDK’s Facilitation
While Lyzr SDK significantly reduces the complexity involved in chatbot creation, it’s essential to acknowledge the myriad external factors still at play. These include critical decisions like selecting the appropriate vector database, utilizing the most effective prompting techniques, and identifying the most suitable LLMs. Each choice in this continuum—from the foundational step of defining the use case to the nuanced selection of RAG techniques—plays a pivotal role in the chatbot’s final efficacy.
Final Thoughts
In sum, building a SOTA Chatbot is a multifaceted endeavor. Lyzr stands as a testament to the possibility of harnessing this complexity into a powerful yet simple to integrate SDK, bringing us closer to realizing the full potential of AI in enhancing business and user experiences alike.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here