


The rise of generative AI has turned “prompt engineering” into one of tech’s favorite buzzwords. Everyone’s looking for that perfect prompt the magic line of text that unlocks the true potential of large language models (LLMs).
But if you’ve ever tried to scale an AI product beyond a demo, you’ve probably realized this: clever prompts can only take you so far.
What truly separates experimental AI from enterprise-grade AI isn’t how well you talk to the model it’s how well you feed it the right information.
That’s where context engineering comes in.
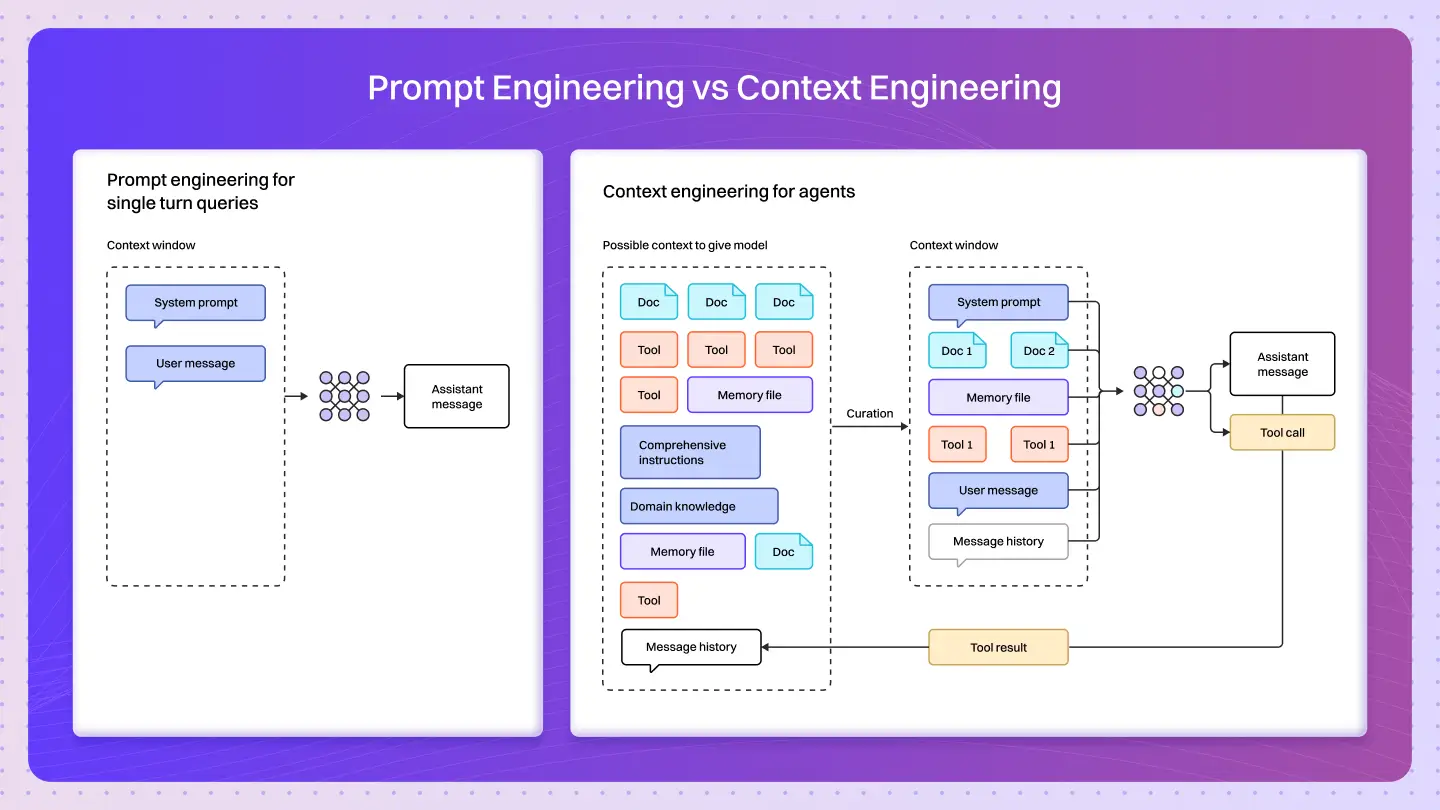
While prompt engineering is about phrasing, context engineering is about architecture designing the ecosystem of data, memory, and tools that an AI agent depends on to think clearly and act reliably.
In this article, we’ll unpack why this shift matters, how context engineering actually works, and who needs to care about it. Whether you’re a developer, product manager, or tech leader, this guide will help you understand the new discipline shaping the future of AI systems.
Understanding Context Engineering
In simple terms, context refers to everything an AI model can “see” or process at a given moment the tokens, data, and memory that shape its reasoning and output.
The engineering challenge?
Optimizing that limited space to include only the most useful, high-impact information so the model consistently performs well across different scenarios.
Thinking in context means going beyond writing good prompts. It’s about understanding the full state the model operates in: what it knows, what it remembers, and what data it can access right now.
That’s where context engineering comes in.
Context Engineering vs. Prompt Engineering

Now that we’ve unpacked what context really means, let’s talk about how it differs from prompt engineering because the two often get mixed up.
Both are important, but they operate at different levels of abstraction.
Here’s the simple way to think about it
- Prompt Engineering works at the linguistic layer. It’s all about how you talk to the model phrasing, tone, and structure. You’re basically saying, “Hey model, here’s exactly how I want you to respond.”
- Context Engineering works at the information layer. This is less about what you say and more about what the model knows. You’re deciding what information enters the model’s context window and how that information is updated, managed, and optimized over time.
So, when you’re prompt engineering, you’re focused on instruction.
When you’re context engineering, you’re focused on intelligence.
And that’s a huge shift.
Because as soon as your AI system starts pulling in external data, remembering past interactions, or reasoning over multiple steps you’re not just prompting anymore. You’re architecting an information ecosystem.
That’s the moment you move from “crafting clever prompts” to designing real agents.
How Context Engineering Works: The Core Building Blocks of Smart AI Systems
If you’ve understood why context matters, the next logical question is “How do you actually engineer it?”
Context engineering isn’t just about feeding the model data it’s about designing how that data flows, evolves, and refreshes over time.
Here are the key building blocks that make it work:
1. Context Window Optimization
Every model has a maximum token limit its working memory.Context engineering is about prioritizing what gets in and what stays out of that window.
- Use summarization techniques to condense past interactions.
- Keep only high-signal tokens (facts, user intent, task-critical data).
- Drop or compress low-value noise (repeated confirmations, filler text, etc).
This ensures the model’s limited attention span is always focused on what truly matters.
2. Memory Management
Unlike static prompts, agents need continuity.
That’s where short-term and long-term memory architectures come in:
- Short-term memory: stores recent turns of conversation (session-level data).
- Long-term memory: stores persistent facts or knowledge across sessions (e.g., user preferences, goals).
- Memory retrieval: uses embeddings or vector databases to bring relevant info back into the model’s active context when needed.
Think of it like the difference between your working notes and your full archive — both critical, but used differently.
3. Tool and Data Orchestration
A well-engineered context doesn’t just contain text it can also include tool outputs, APIs, or external knowledge sources.
- Integrate APIs to fetch live or domain-specific data.
- Use structured context formats (like JSON schemas or Model Context Protocols).
- Keep your context consistent, so the model never has to “guess” data structure.
This turns your model into a reasoning system rather than a text generator.
4. Context Refresh and Refinement Loops
Over time, agents accumulate noise irrelevant logs, outdated data, redundant summaries.
That’s why context engineering involves continuous refinement loops:
- Prune irrelevant data periodically.
- Re-summarize and compress older memory.
- Dynamically re-rank relevance before each new inference cycle.
This keeps your agent agile, accurate, and contextually aware no matter how long it runs.
Why Context Engineering Matters for Building Capable AI Agents
Let’s be honest even the most advanced large language models (LLMs) have limits.
They’re fast, powerful, and can process mind-boggling amounts of data… but like humans, they eventually lose focus.
You’ve probably seen it: you give your AI a long thread of instructions or questions, and suddenly, it starts missing details or contradicting itself. That’s not carelessness it’s what researchers call context rot.
What Is Context Rot?
As the number of tokens (the words and data you feed into an LLM) increases, the model’s ability to accurately recall and reason over that information starts to drop.
Think of it like a conversation the longer it gets, the harder it becomes to remember what was said 10 minutes ago unless you’re actively managing it.
Here’s what happens under the hood:
- Every LLM has a context window a limited space for tokens it can “see” at once.
- As that window fills up, the model starts to forget older or less relevant information.
- This leads to confusion, reduced precision, or contradictory outputs.
In other words, context is a finite resource and once it’s stretched too thin, performance drops.
How to Write Better Contexts: The Art and Practice of Context Optimization
Now that we know why context engineering matters and how it works, let’s talk about the hardest part writing and maintaining great contexts.
Because a powerful agent doesn’t just depend on clever prompts or fancy APIs.
It depends on how well you curate what the model sees and understands at any given time.
Good context engineering means finding the smallest possible set of high-signal tokens that consistently drive the desired outcome. But getting there takes experimentation, structure, and discipline.
Let’s break it down into actionable principles
1. Calibrate Your System Prompts
Your system prompt is the foundation of your agent’s behavior.
It defines tone, task boundaries, and reasoning style so it must be clear, concise, and at the right altitude.
Think of “altitude” as the Goldilocks zone between two extremes:
- Too detailed: Hardcoded if-else logic that makes your agent brittle and hard to maintain.
- Too vague: Abstract, high-level instructions that assume the model “gets it.”
- ✅ Just right: Specific enough to guide outputs, flexible enough for intelligent reasoning.
Tips for better system prompts:
- Use clear structure: divide sections like
<background_information>, <task_instructions>, ## Tool usage, and ## Output format. - Use Markdown or XML-style tags to help the model parse context more effectively.
- Start minimal. Test with the strongest model available, analyze failure cases, and then refine.
2. Design Tools That Support Efficient Thinking
Tools act as the hands and eyes of your agent.They define how it interacts with external data and therefore how much extra context it can dynamically retrieve.
Best practices for building token-efficient tools:
- Keep tool functionality simple and distinct. Avoid overlapping capabilities.
- Make input parameters descriptive and unambiguous.
- Return compact, structured outputs (like JSON) that don’t waste tokens.
- Prioritize clarity over cleverness. The LLM should immediately understand the tool’s purpose.
3. Use Examples Wisely (Few-Shot Prompting Done Right)
Examples, or few-shot prompts, are still one of the best ways to guide model behavior.
But many teams go wrong by overloading prompts with every possible edge case.
What works better:
- Curate a handful of diverse, canonical examples that capture your core logic.
- Each example should demonstrate the pattern of reasoning you want the agent to follow.
- Refresh examples periodically as your task or model evolves.
4. Keep Context Tight and Dynamic
Even the best-designed prompts degrade over time if you don’t prune and refresh them.
As your agent runs across multiple inference loops, its context fills up with irrelevant or outdated data what we call context rot.
To prevent that:
- Continuously summarize and compress message history.
- Drop redundant or low-value text before each new cycle.
- Retrieve only the most relevant memory chunks at runtime using vector search or embeddings.
- Periodically revalidate your context window for token efficiency.
Context engineering marks a fundamental shift in how we build and scale with large language models.
As LLMs become more powerful, the real challenge isn’t about crafting the perfect prompt anymore it’s about curating the right context at every step of the reasoning process.
Whether you’re:
- Implementing context compaction for long-horizon tasks,
- Designing token-efficient tools for your agent, or
- Enabling real-time retrieval to keep your AI aware of its environment
the guiding principle remains the same:
Find the smallest, highest-signal set of tokens that drive the best possible outcome.
The future of AI engineering lies not in controlling what the model says, but in designing what it sees its memory, environment, and information flow.
As models continue to evolve, we’ll need less prescriptive logic and more adaptive systems. But one thing won’t change:
Treating context as a precious, finite resource will always be key to building reliable, grounded, and scalable AI agents.
Ready to start context engineering?
You can explore and build your own context-aware AI agents with Lyzr Agent Studio a no-code / low-code platform that lets you design, orchestrate, and deploy intelligent agents in minutes.
It’s the easiest way to put these principles into practice and build agents that don’t just respond they reason.
FAQs
1) What is Context Engineering?
It’s the process of shaping what information an AI sees before generating output.
Instead of just prompting, you design the space the model thinks inside.
2) How is it different from Prompt Engineering?
Prompting is asking whereas Context Engineering is setting roles, rules, memory, tone, and knowledge so the answer is consistently good.
3) Why does context matter so much?
LLMs don’t understand they pattern-match.So the context you feed decides the quality you get back.
4) What is included in “context”?
System instructions, goals, constraints, reference docs, user history, examples, tone, and formatting guidelines.Basically everything around the prompt.
5) Do I need fine-tuning if I do Context Engineering well?
Often no.
Good context reduces hallucination and improves accuracy without retraining the model.
Book A Demo: Click Here
Join our Slack: Click Here
Link to our GitHub: Click Here